Het beveiligen van uw software-toeleveringsketen begint met de ontdekking en het beheer van uw 'softwarefabriek'
In de huidige softwareontwikkelingsomgeving hanteren teams gedecentraliseerde assets zoals coderepositories, buildpipelines en containerimages. Hoewel dit gedistribueerde model flexibiliteit biedt en de productie versnelt, fragmenteert het ook assets en compliceert het governance en beveiligingstoezicht, vooral omdat cloud-native applicaties steeds wijdverspreider worden.
Als gevolg hiervan verliezen beveiligingsteams vaak kostbare tijd met het opsporen van code-eigenaren voor verweesde productiewerklasten wanneer er beveiligingsproblemen ontstaan of wanneer niet-goedgekeurde software-artefacten hun weg naar productie vinden. De software-toeleveringsketen is een kritisch aanvalsoppervlak geworden en het is essentieel om beveiligingssignalen vroeg te verzamelen - van ontwikkeling tot en met de bouwfase - om blinde vlekken te voorkomen en ervoor te zorgen dat alle activa in de Software Development Lifecycle (SDLC) worden bewaakt.
DevSecOps-teams hebben doorgaans geen geautomatiseerde tools om dit veranderende ontwikkelingslandschap continu in kaart te brengen, waarbij regelmatig nieuwe codepaden en tools worden geïntroduceerd. Informatie blijft vaak over verschillende platforms verspreid, waardoor het moeilijk toegankelijk is voor beveiligingsdoeleinden. Dev-platforms en tools variëren vaak tijdens de ontwikkeling, integratie en implementatie, aangezien software door de fasen heen wordt gepromoot.
Leveranciers van Application Security Posture Management (ASPM) en observability bundelen weliswaar beveiligingsscans, maar bieden vaak geen compleet overzicht van de codepaden naar de productieomgeving.
De aanwezigheid van verouderde assets verergert het probleem. Het identificeren van welke repositories nog steeds actief zijn in productie kan overweldigend zijn, met name voor grote organisaties. Fusies en overnames compliceren dit verder door het toevoegen van diverse platforms en ontwikkelingsnormen.
DevSecOps-teams grijpen vaak terug op handmatige processen, zoals het invullen van manifesten of het labelen van containers. Deze processen zijn vervelend, foutgevoelig en worden vaak opzijgezet ten gunste van dringender prioriteiten.
Zie het als het verdedigen van een voortdurend veranderend slagveld, waar beveiligingsteams een nauwkeurige kaart nodig hebben om hun activa te beschermen. Deze activa zijn altijd in ontwikkeling en nieuwe doelen moeten worden geïdentificeerd en beveiligd. Om dit aan te pakken, is een doorlopend ontdekkingsmechanisme vereist om veranderingen in kaart te brengen terwijl ze plaatsvinden.
Best practices en frameworks ondersteunen deze aanpak. Bijvoorbeeld de Agentschap voor cyberbeveiliging en infrastructuurbeveiliging (CISA) vereist dat organisaties de herkomst van softwarecomponenten verifiëren en een uitgebreide inventaris bijhouden als onderdeel van hun zelf-attestatieproces. Evenzo, de NIST Secure Software Development Framework (SSDF) en OWASP DevSecOps-volwassenheidsmodel (DSOMM) benadrukken het belang van voortdurende ontdekking en zichtbaarheid.
In de rest van dit bericht schetsen we een blauwdruk voor het aanpakken van deze uitdagingen en onderzoeken we hoe Scribe Security organisaties helpt deze mogelijkheden effectief te implementeren.
Scribe's blauwdruk voor effectieve ontdekking
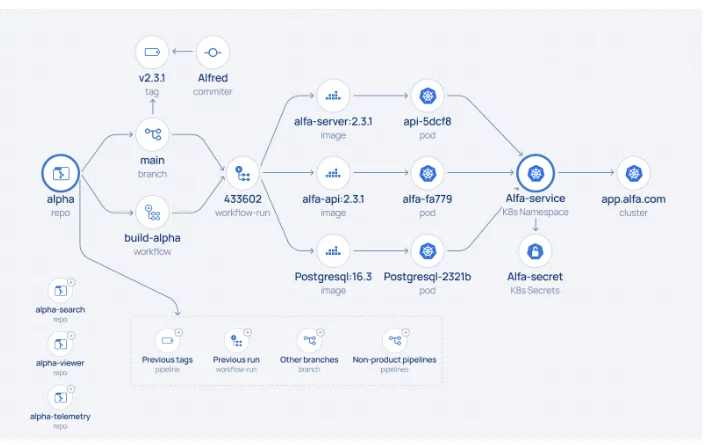
Discovery genereert een kaart die is gemodelleerd in een grafiek, die een overzicht biedt van activa, relaties en de beveiligingshouding van uw fabriek. Dit maakt het mogelijk om:
- Volledig inzicht en controle over het eigendom.
- Verbeterde querymogelijkheden.
- Monitoring van KPI's en beveiligingsvolwassenheidscijfers.
- Snellere identificatie en prioritering van risicofactoren.
- Eerste scan
De eerste scan is bedoeld om een high-level map van assets te maken, met de focus op het identificeren van die assets die verdere analyse nodig hebben. Een volledige deep scan kan tijdrovend zijn en veel assets, zoals assets die niet gekoppeld zijn aan productie of verouderd zijn, kunnen irrelevant zijn. Deze eerste scan verzamelt doorgaans basisgegevens zoals repositorynamen, ID's en activiteitsstatistieken, maar bevat geen volledige lijst met commits of bijdragers.
Eén methode is scannen van 'rechts naar links'. Door toegang te krijgen tot productieomgevingen (bijvoorbeeld via de K8s cluster API), kan de scanner actieve containerimages identificeren: kritieke assets die de bedrijfswaarde weerspiegelen. Van daaruit traceert de scan terug naar het containerregister en relevante repositories. De scan stopt hier meestal, omdat er doorgaans geen directe verbinding is tussen het register en de voorafgaande SDLC-pijplijn.
Aanvullende scans kunnen van 'links naar rechts' worden uitgevoerd, waarbij codeopslagplaatsen, build-pipelines en registers in verschillende SDLC-fasen (bijvoorbeeld ontwikkeling, integratie, testen) worden geïdentificeerd.
Het resultaat is een geprioriteerde lijst van activa op verschillende platforms, klaar voor diepgaand scannen om de afstamming van code tot productie te traceren en de beveiligingshouding van de SDLC te beoordelen. Prioritering is gebaseerd op factoren zoals relevantie voor productie, activiteitsniveau en recentie. Soms helpt institutionele kennis van de significantie van activa om dit proces te begeleiden.
De eerste scan kan periodiek worden gepland of worden geactiveerd door gebeurtenissen zoals code pushes. Volgende scans kunnen automatische selectiecriteria toepassen, zoals het gebruik van globs voor deep scanning van nieuw ontdekte assets.
- Diepe scan
Zodra relevante assets zijn geprioriteerd, verzamelt de deep scan gedetailleerde kenmerken die relaties tussen assets vaststellen, zoals branch-ID's, commit- en committer-ID's en pipeline run-ID's. De duur van deze scan kan variëren, afhankelijk van de scope van de assets en API-snelheidslimieten.
Aan het einde van deze fase begint een asset relationship graph vorm te krijgen, met clusters van verbonden assets rond code repositories (met buildinformatie) en runtime-omgevingen (met registerassets). Een complete lineage is echter nog niet compleet, omdat registers doorgaans geen informatie opslaan over de pipelines die de build-artefacten pushten.
- Clusters verbinden
Zodra de inventaris is vastgesteld, kan de lineage worden voltooid door een CLI-tool in de pijplijn te instrumenteren om details van de build-herkomst vast te leggen of door CI-logs te verwerken. Instrumentatie is de meest betrouwbare methode, waarbij belangrijke kenmerken worden vastgelegd, zoals coderepository-ID's, pijplijn- en run-ID's en image-ID's. Het koppelt eerder geïsoleerde clusters effectief en creëert een complete end-to-end lineage van code tot productie.
Een complementaire aanpak is CI log processing, die relevante kenmerken ophaalt maar meer resources vereist en afhankelijk is van bestaande logging. Hoewel deze methode een snellere implementatie biedt, levert de combinatie van beide aanpakken de beste resultaten op: het instrumenteren van kritieke pipelines en het gebruiken van loganalyse voor nieuw ontdekte pipelines, die vervolgens kunnen worden geëvalueerd voor verdere instrumentatie.
Deze clusterbenadering houdt ook rekening met het samenvoegen van afzonderlijke productlijnen in een uniforme structuur voor complexe producten, zoals webapplicaties die bestaan uit meerdere componenten, zoals microservices.
- Software Stuklijst (SBOM)
Tot nu toe lag de focus op het verbinden van ontwikkelingsactiva over platformen heen, waarbij een duidelijke afstamming van code naar productie voor relevante activa werd vastgesteld. Nu verschuift de aandacht naar de samenstelling van de softwareartefacten zelf. In deze stap wordt een SBOM gegenereerd van die artefacten en hun bijbehorende coderepositories, en worden ze toegevoegd aan de bestaande inventaris.
Door een coderepository en artefact-SBOM's te synthetiseren tot één SBOM, met logica om afhankelijkheden te correleren en irrelevante afhankelijkheden uit te sluiten (zoals ontwikkelings- en testbibliotheken), is het resultaat een nauwkeurigere en uitgebreidere SBOM dan beide bronnen afzonderlijk zouden kunnen bieden.
- Beveiligingshouding en DevSecOPs KPI's
Het continu in kaart brengen van de inventaris van activa en hun relaties biedt de beste mogelijkheid om de beveiligingspositie van deze activa te beoordelen. Belangrijke factoren zijn toegangsrechten voor menselijke en niet-menselijke identiteiten, verificatie van codehandtekeningen, riskante of kwetsbare afhankelijkheden en beveiligingsinstellingen op verschillende platforms en accounts.
Deze gegevens kunnen worden samengevoegd in verschillende dimensies om KPI's te meten voor productreleases, implementatietijden naar productie en DevSecOps-volwassenheid. Het stelt teams met name in staat om de acceptatie van beveiligingscontroles te evalueren, zoals codeondertekening en naleving van beveiligingsinstellingen, wat helpt om de voortgang bij te houden en robuuste beveiligingspraktijken te garanderen.
- Visualisatie en bevraging van de SDLC- en software-toeleveringsketengrafiek
Een belangrijk voordeel van het ontdekkingsproces is de mogelijkheid om de SDLC en software-toeleveringsketen te visualiseren als een dynamische grafiek of 'battle map'. Deze visualisatie biedt een uitgebreid overzicht van de volledige ontwikkelingscyclus, waardoor het volgen van activa en hun relaties eenvoudiger wordt.
De echte kracht zit in de mogelijkheid om de grafiek te bevragen, waardoor teams kritische vragen kunnen stellen, zoals:
- “Welk onderdeel heeft een beveiligingscontrole tijdens de build of implementatie niet doorstaan?”
- “Welke workloads in de productie worden als wees beschouwd?”
- “Wie heeft de verandering doorgevoerd die een kwetsbaarheid heeft geïntroduceerd?”
- “Wie is de eigenaar van het item dat gepatcht moet worden?”
Door de lineage te bevragen, kunnen teams de hoofdoorzaak van problemen identificeren, wat een duidelijk voordeel is ten opzichte van handmatige documentatie. Handmatig onderhouden ownership mappings raken snel verouderd, wat DevSecOps-teams vaak leidt tot inefficiënte zoekopdrachten naar de juiste stakeholders. Een queryable graph zorgt er daarentegen voor dat ownership en accountability altijd up-to-date zijn, waardoor er minder tijd verloren gaat aan het achterhalen van de verantwoordelijkheid voor code of infrastructuur.
- Implementatieopties voor Discovery Tools
Organisaties hebben uiteenlopende behoeften voor het implementeren van discovery tools en het aanbieden van flexibele implementatieopties is essentieel om te voldoen aan verschillende beveiligingsvereisten. Sommige teams geven de voorkeur aan externe toegang via een SaaS-platform, wat het beheer en de schaalbaarheid vereenvoudigt. Aan de andere kant kunnen teams met strengere beveiligingsprotocollen kiezen voor lokale scannerimplementatie om een strakkere controle te behouden over gevoelige inloggegevens, zoals API-tokens voor ontwikkelingsplatforms. De keuze tussen SaaS en lokale implementatie hangt af van factoren zoals de beveiligingshouding van de organisatie, nalevingsbehoeften en controle over gegevens.
Conclusie
Het beveiligen van uw software supply chain is een voortdurende strijd; geen enkele organisatie zou eraan moeten beginnen zonder een duidelijke kaart. Door een robuust discovery-proces te implementeren, krijgt u uitgebreid inzicht in uw SDLC en supply chain, zodat u zeker weet dat elk activum verantwoord is, van ontwikkeling tot productie. Met tools zoals de blueprint van Scribe Security kunt u een verbonden lineage bouwen, nauwkeurige SBOM's genereren, uw beveiligingshouding beoordelen en kritieke relaties binnen uw ontwikkelingsecosysteem visualiseren. Dit niveau van inzicht stelt DevSecOps-teams in staat om kwetsbaarheden snel te identificeren, hun oorsprong te traceren en een up-to-date begrip van hun softwarelandschap te behouden - essentieel om voorop te blijven lopen in de snelle en complexe ontwikkelomgeving van vandaag.
Schriftgeleerde biedt een uitgebreide oplossing voor Discovery en governance als een cruciale factor voor het beveiligen van uw softwaretoeleveringsketen:
- Initiële en diepe scans – Identificeert en prioriteert activa zoals codeopslagplaatsen, pijplijnen en containerimages in verschillende omgevingen en maakt een inventaris van relevante componenten.
- End-to-End-afstamming – Verbindt geïsoleerde assetclusters met behulp van CLI-tools en CI-logs, waardoor een volledige lijn ontstaat van code tot productie.
- Software Stuklijst (SBOM) – Genereert nauwkeurige SBOM's door artefact- en repositorygegevens te synthetiseren, waarbij irrelevante afhankelijkheden worden uitgesloten.
- Beoordeling van de veiligheidshouding – Evalueert voortdurend toegangscontroles, codehandtekeningen en kwetsbare afhankelijkheden om beveiligings-KPI's te meten.
- Visualisatie en query's – Visualiseert de volledige SDLC en maakt query's mogelijk om kwetsbaarheden, verweesde workloads en eigendom van activa te traceren.
- Flexibele inzet – Ondersteunt zowel SaaS als lokale implementaties om te voldoen aan uiteenlopende beveiligingsbehoeften en controle over gevoelige gegevens.
Deze inhoud wordt u aangeboden door Scribe Security, een toonaangevende aanbieder van end-to-end software supply chain-beveiligingsoplossingen die state-of-the-art beveiliging levert voor codeartefacten en codeontwikkelings- en leveringsprocessen in de software supply chain. Meer informatie.
Gerelateerde berichten


