De industrie heeft het idee van een SBOM nog niet volledig begrepen en we hoorden al een nieuwe term – ML-BOM – Machine Learning Bill of Material. Laten we, voordat er paniek uitbreekt, eerst begrijpen waarom zo'n stuklijst moet worden geproduceerd, wat de uitdagingen zijn bij het genereren van een ML-BOM en hoe zo'n ML-BOM eruit kan zien.
Terwijl je deze blog leest, vraag je je misschien af of dit artikel door AI is gegenereerd. De reden is dat AI overal om ons heen is, en het moeilijk is om het te onderscheiden van door mensen gemaakte artefacten. De snelle ontwikkelingen op het gebied van AI brengen echter ook particuliere, commerciële en maatschappelijke risico’s met zich mee, en er begint wetgeving uit te rollen om deze risico’s te beperken, bijvoorbeeld door de EU AI-wet. Het valt buiten het bestek van dit artikel om diep in te gaan op deze risico’s, maar om er een paar te noemen: er zijn risico’s van onveilig, discriminerend en privacyschendend gedrag van door AI aangedreven systemen, evenals van IP, licenties en cybercriminaliteit. -veiligheidsrisico's.
Een eerste stap bij het omgaan met deze risico’s is weten welke AI-technologieën binnen elk systeem worden gebruikt; dergelijke kennis kan belanghebbenden in staat stellen de risico's te beheersen (bijvoorbeeld juridische risico's te beheersen door de licentie van datasets en modellen te kennen) en te reageren op nieuwe bevindingen met betrekking tot deze technologieën (bijvoorbeeld als een model discriminerend blijkt te zijn, kan de belanghebbende alle systemen die dit model gebruiken om het risico te beperken).
Een blik werpen op de evoluerende regelgeving, onderzoeken Executive Order 13960 over “Bevordering van het gebruik van betrouwbare kunstmatige intelligentie in de federale overheid” onthult principes als verantwoording, transparantie, verantwoordelijkheid, traceerbaarheid en toezicht op de regelgeving – die allemaal vereisen dat we begrijpen welke AI-technologieën in elk systeem worden gebruikt.
Een ML-BOM is een documentatie van AI-technologieën binnen een product. CycloneDX, het bekende OWASP-formaat voor SBOM, versie 1.5 en hoger, ondersteunt het en is nu een standaard voor ML-BOM.
Het genereren van een ML-BOM is een uitdaging; er zijn veel manieren om modellen en datasets weer te geven; AI-modellen en datasets kunnen on-the-fly worden geconsumeerd, en de beslissing over welke modellen te gebruiken kan programmatisch en on-the-fly worden genomen, zonder sporen achter te laten voor standaard componentanalysetechnologieën om ze te detecteren. Naast deze uitdagingen is AI nog steeds een opkomende technologie, in tegenstelling tot de volwassenheid van softwarepakketbeheerders. De industrie begrijpt dus nog niet volledig de behoeften van een ML-BOM.
Als uitgangspunt hebben we besloten ons te concentreren op het genereren van een ML-BOM voor projecten die een de facto standaard gebruiken, HuggingFace. HuggingFace is een ‘pakketbeheerder’ voor AI-modellen en datasets en wordt vergezeld door populaire Python-bibliotheken. Hieronder volgen enkele snapshots van een SBOM die we automatisch op basis van een dergelijk product hebben gegenereerd.
Stel je een product voor dat uit veel componenten bestaat, waarvan sommige machine learning-modellen zijn. De onderstaande CycloneDX-component beschrijft een dergelijk model:
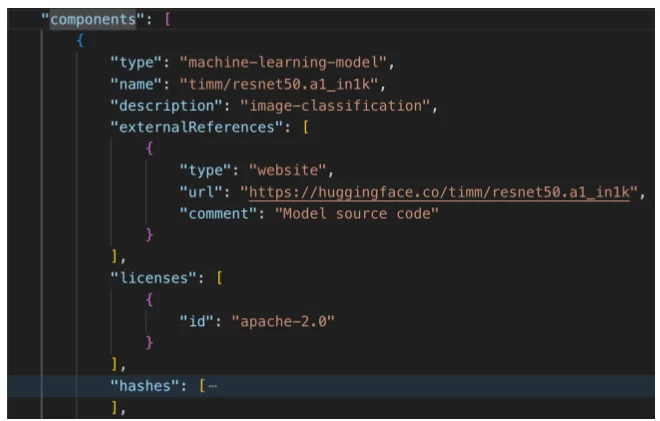
Machine-learning-modelcomponent (deel 1) – standaard CycloneDX-componentgegevens
Dit onderdeel identificeert het model en biedt een link waarmee u informatie over dit model verder kunt verkennen. Daarnaast bevat het licentie-informatie die kan worden gebruikt voor nalevingsdoeleinden.
CycloneDX V1.5 definieert ook een AI-specifiek veld met de naam “modelCard” als een standaardmanier om machine learning-modeleigenschappen te documenteren. Hieronder volgt een voorbeeld van een modelCard die we hebben gemaakt.
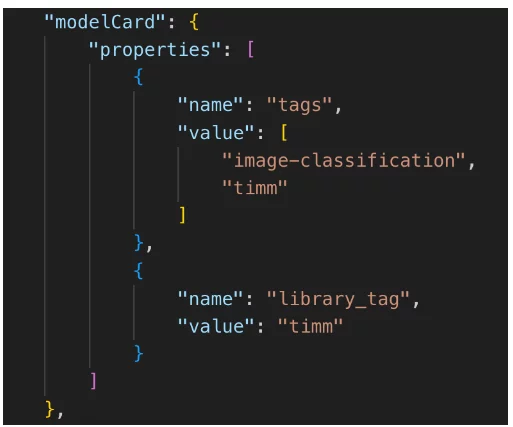
Machine-learning-modelcomponent (deel 2) – datakaart
Een gebruiksscenario voor een dergelijke modelCard kan het vinden van alle producten zijn die beeldclassificatiemodellen gebruiken of het uitvoeren van een beleid dat het gebruik van specifieke modeltypen verhindert.
CycloneDX maakt de documentatie van een componentenboom – subcomponentenhiërarchie mogelijk. Omdat HuggingFace, als AI-pakketbeheerder, AI-modellen en datasets representeert als git-repos, hebben we besloten om de bestanden van het AI-model/dataset te documenteren als subcomponenten van de machine learning-modelcomponent. Dit is hoe het eruit ziet:
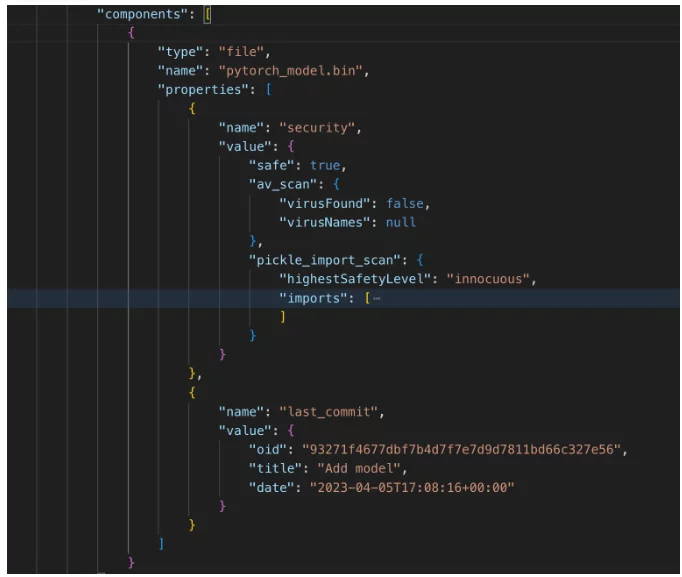
Machine-learning-modelcomponent (deel 3) – subcomponenten
Naast de standaardbestandsinformatie bevatten de eigenschappen aanvullende informatie, zoals beveiligingsinformatie. In dit geval zien we twee beveiligingsmaatregelen:
- Virusscannen – is belangrijk bij het gebruik van datasets die vatbaar zijn voor virussen (zoals afbeeldingen, PDF's en uitvoerbare bestanden).
- Pickle-scannen – beveiligingsrisicomaatregelen met betrekking tot datasetbestanden van het type “pickle”, die meer risico lopen (om de risico’s in dit formaat te begrijpen, zie de uitleg op de HuggingFace-website).
Deze gegevens kunnen worden gebruikt om beleid af te dwingen dat verifieert dat het scannen op virussen en augurken met succes is uitgevoerd.
ML-BOM is een nieuw concept; wat we hier laten zien is een eerste stap. Maar zelfs als zodanig kunnen we de waarde ervan begrijpen, gezien de toenemende adoptie, regulering en risico’s van AI.
Als laatste opmerking vroeg ik mijn kristallen bol (ook bekend als ChatGPT) om de toekomst van ML-BOM's te beschrijven, en dit was het antwoord:
“In de niet zo verre toekomst zouden ML-BOM’s misschien wel kunnen evolueren naar cyber-savvy, autopiloting maestro’s, die de symfonie van machine learning-modellen orkestreren met een flair van automatisering, en dat allemaal terwijl ze door de complexiteit van CI/CD-pijplijnen tapdansen. .”
Nou ja, misschien hebben we meer nodig dan alleen ML-BOM's...
Deze inhoud wordt u aangeboden door Scribe Security, een toonaangevende aanbieder van end-to-end software supply chain-beveiligingsoplossingen die state-of-the-art beveiliging levert voor codeartefacten en codeontwikkelings- en leveringsprocessen in de software supply chain. Meer informatie.
Gerelateerde berichten


