CVE (Общие уязвимости и риски) сканирования необходимы для защиты ваших программных приложений. Однако с ростом сложности программных стеков выявление и устранение всех CVE может оказаться сложной задачей. Одной из самых больших проблем при сканировании CVE сегодня является распространенность ложных срабатываний, когда уязвимость обнаруживается в пакете, который не используется в рабочем приложении.
Важно помнить, что даже если вы получили полный список всех ваших пакетов программного обеспечения и полный список всех CVE, найденных в этих пакетах, вполне вероятно, что не все из них имеют отношение к вашему приложению. CVE может находиться в функции, которая не используется в вашем коде, или в части библиотеки, которую вы даже не вызываете. Это может быть временная зависимость, которая вызывается только из-за неисправленного списка зависимостей и вообще не используется в вашем коде. Даже если вы знаете, что CVE находится в части используемой вами библиотеки, это не гарантирует, что CVE действительно можно использовать в вашем приложении. Некоторые эксплойты могут быть использованы хакерами в экстремальных условиях, включая комбинацию трех или более последовательных CVE, правильный стек и правильную инфраструктуру. Поскольку вам все равно нужно более внимательно изучить каждую CVE, полученную в результате сканирования, вы можете увидеть, насколько важно отсеять количество полученных CVE, чтобы вы не устали от оповещений или не перегорели CVE, прежде чем сможете вернуться. к фактическому созданию следующих функций вашего приложения.
В этой статье я предложу некоторые возможные решения по уменьшению количества ложных срабатываний при сканировании CVE, стремясь уменьшить общее количество CVE, с которыми вам придется иметь дело. Я начну с обсуждения проблем идентификации пакетов, а затем перейду к знакомству с базой данных, которая сопоставляет файлы пакетов с именами пакетов. Я также расскажу о проблемах с областью действия и путями кода, которые могут привести к ложным срабатываниям.
Давайте начнем с рассмотрения того, как выявляются CVE.
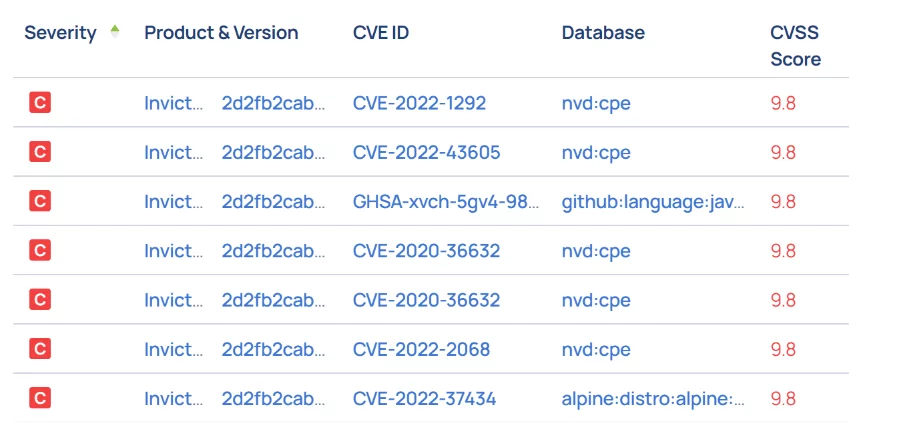
Таинственный пакет и пропавший CVE
Mitre Corporation — американская некоммерческая организация, отвечающая за программа CVE®. Программа Миссия заключается в выявлении, определении и каталогизации публично раскрытых уязвимостей кибербезопасности. Это работает так: как только вы обнаруживаете уязвимость, вы заполняете форму, и, если находка может быть подтверждена, уязвимости присваивается новый идентификатор CVE, и она добавляется в общедоступную базу данных CVE.
Учитывая способ перечисления CVE, одной из основных проблем при сканировании CVE является правильная идентификация пакетов и библиотек. Когда кто-то обнаруживает уязвимость в пакете или библиотеке, он указывает ее с именем пакета и версией, с которой он знаком. Конечно, не все инструменты используют одни и те же соглашения об именах, а имена пакетов не имеют глобального стандарта. «Проблема именования», как ее стали называть, настолько серьезна, что множество форумов и аналитических групп уже долгое время пытаются найти общее решение. В качестве примера, вот Предлагаемое решение OWASP по проблеме, связанной с созданием SBOM. Часто инструменты сканирования полагаются на источники, которые им передаются, например, собранные или скомпилированные артефакты, для имен пакетов, которые они предоставляют в результатах сканирования, и эти источники не всегда надежны. Например, обертки и приспособления могут затруднить идентификацию фактической упаковки. Кроме того, некоторые файлы пакетов могут не оставлять следов своего установочного пакета, например команды Docker COPY.
Для решения этих проблем мы, в Писец безопасности, предложите создать для вашего приложения базу данных, которая сопоставляет файлы пакетов с именами пакетов. Даже если имя пакета отличается, если это один и тот же пакет, файлы и хэши файлов будут идентичны. Поступая так, вы можете пропустить проблемы, связанные с оболочками и адаптациями, и определить фактический пакет, который необходимо устранить. Такой подход может сэкономить время и усилия в процессе устранения CVE. Поскольку Платформа Писца уже идентифицирует файлы, связанные с каждым пакетом, включенным в ваш окончательный образ, создание такой базы данных является следующим логическим шагом. Мы предполагаем, что наше сканирование CVE не должно будет полагаться на имя и версию, указанные в CVE, а на фактические файлы, которые входят в пакет.
Ты моя мамочка?
При работе с окончательной сборкой, представляющей собой образ Docker, в наши дни принято не начинать с нуля. Наличие надежной отправной точки, такой как установленный базовый образ, позволяет разработчикам сосредоточиться на той части сборки, которая представляет собой их приложение, а не начинать планировать среду, в которой оно должно работать. Одной из проблем при использовании образов Docker является понимание их происхождения и зависимостей, особенно когда речь идет о родительском образе (помимо базового образа), поверх которого создается окончательный образ.
Родительский образ — это концепция, которую мы придумали для объяснения ближайшего «живого родственника» образа Docker. Образы создаются в отдельных слоях, поэтому, допустим, я использую известный базовый образ, например Alpine, Debian или Ubuntu, и создаю слой приложения прямо поверх него. В этом случае моим ближайшим «родителем» будет это базовое изображение. Но что, если компания, в которой я работаю, имеет другую отправную точку, включающую базовый образ и еще несколько уровней поверх инструментов безопасности, которые являются обязательными для всех образов компании? В этом случае моим родительским изображением будет этот шаблон компании, и я также смогу идентифицировать базовое изображение, на котором был построен этот шаблон.
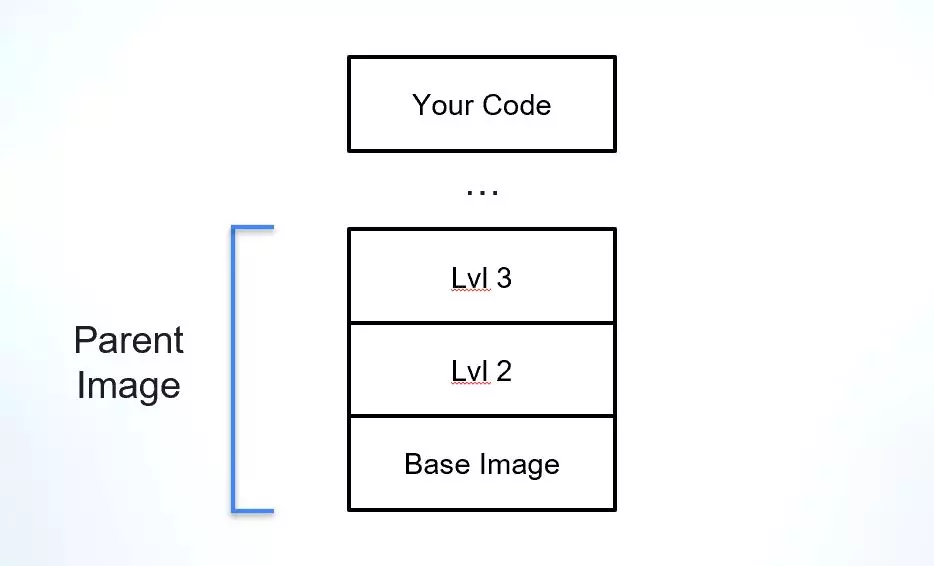
Родительский образ — важнейшая часть вашей цепочки поставок программного обеспечения, поскольку он обеспечивает основу для приложения и его зависимостей. Образы Docker изначально не содержат много информации о происхождении родительских или базовых образов, что затрудняет проверку их целостности, понимание уязвимостей и проверку лицензии.
Чтобы решить эту проблему, Scribe разработала инструмент и сервис с открытым исходным кодом под названием Родительское изображение для обнаружения ближайшего отсканированного родителя образа Docker. Этот инструмент можно использовать для идентификации родительского образа образа Docker, что является ключевым фактором снижения риска:
Во-первых, идентифицировав базовый образ, можно проверить его целостность и убедиться, что он не был подделан или скомпрометирован. Это важно для поддержания безопасности и стабильности приложения.
Во-вторых, понимая, какие уязвимости происходят из родительского образа, а какие — из самого уровня приложения, можно более эффективно расставлять приоритеты и управлять уязвимостями. Это означает, что CVE, связанные с вашим базовым или родительским образом, менее срочны (и не всегда вы несете ответственность за исправление) по сравнению с CVE на уровне приложения.
Кроме того, идентифицировав родительское изображение, можно проверить его лицензию и обеспечить соответствие требованиям законодательства и внутренней политики.
Инструмент с открытым исходным кодом ParentImage включает обновляемую базу данных сканированных изображений Docker. Вы можете его форкнуть и использовать полностью внутри компании, но мы надеемся, что люди будут сканировать свои образы Docker и присылать нам эту информацию для включения в базу данных. Чем больше сканирований изображений содержится в базе данных, тем больше «родителей» сможет идентифицировать инструмент. В настоящее время включенная база данных содержит полный список всех установленных базовых изображений в качестве доказательства концепции. Поскольку это инструмент с открытым исходным кодом, его попробовать ничего не стоит, поэтому, если вы используете образы Docker, я рекомендую вам рассмотреть этот инструмент как возможное средство устранения одной из причин несвязанных CVE.
Стоит ли сканировать или пропустить?
Еще одна проблема при сканировании CVE — проблемы с областью действия. Под определением области понимается расположение сканируемых файлов и пакетов: что следует включить в сканирование, а что можно безопасно игнорировать. Иногда CVE находится в пакете, который фактически не используется в производственной версии приложения. Например, пакет может быть установлен в результате косвенной зависимости от некоторой среды тестирования. Чтобы решить эту проблему, сканерам необходимо оценить объем файлов приложения и выявить используемые косвенные зависимости.
Плагины OWASP (The Open Worldwide Application Security Project) содержат несколько хороших примеров инструментов, которые могут помочь в решении проблем с областью действия. Проверка зависимостей OWASP, например, может анализировать зависимости приложения и выявлять CVE в контексте графа зависимостей приложения. Таким образом, он может определить, какие CVE используются в рабочем приложении, а какие нет.
Каким бы ни было число, вам все равно нужно бороться с CVE
В отсутствие какого-либо другого инструмента, который мог бы сказать вам, где ваше приложение уязвимо для возможных взломов, бэкдоров и других подобных проблем, сканирование CVE по-прежнему остается довольно простым вариантом решения потенциальных проблем. Проблема в том, что до тех пор, пока вы не проверите, является ли CVE, представленный вам при сканировании, реальной проблемой, он представляет собой угрозу, которую могут использовать против вас как регулирующие органы, третьи лица, так и пользователи.
Во имя безопасности и прозрачности вам необходимо изучить каждую потенциальную проблему и доказать, что она либо не проблема, не имеет отношения к вашему приложению, либо это потенциальная проблема, и вы работаете над ее исправлением. Тот факт, что многие из этих CVE попадают в ваше приложение из внешних пакетов, обычно с открытым исходным кодом, означает, что даже если вы определите это как потенциальный эксплойт, вам, вероятно, все равно понадобится помощь сопровождающих пакетов для его исправления.
Учитывая всю эту работу, связанную с каждым CVE, неудивительно, что вы предпочитаете получить как можно меньшее число при следующем сканировании CVE. Использование некоторых рекомендаций, изложенных в этой статье, может помочь сделать монументальную задачу устранения уязвимостей немного более выполнимой.
Если у вас есть другие инструменты с открытым исходным кодом или бесплатные инструменты для решения этой проблемы, мы будем рады услышать об этом. Расскажите об этом в комментариях и поделитесь с сообществом, как вы справляетесь со своей горой уязвимостей.

Этот контент предоставлен вам Scribe Security, ведущим поставщиком комплексных решений для обеспечения безопасности цепочки поставок программного обеспечения, обеспечивающим современную безопасность артефактов кода, а также процессов разработки и доставки кода по всей цепочке поставок программного обеспечения. Подробнее.
Статьи по теме


