Отрасль еще не до конца осознала идею SBOM, и мы уже начали слышать новый термин — ML-BOM — ведомость материалов машинного обучения. Прежде чем начнется паника, давайте разберемся, почему такая спецификация должна быть создана, какие проблемы возникают при создании ML-BOM и как может выглядеть такая ML-BOM.
Читая этот блог, вы можете спросить себя, была ли эта статья создана искусственным интеллектом. Причина в том, что ИИ окружает нас повсюду, и его трудно отличить от искусственных артефактов. Однако быстрый прогресс в области искусственного интеллекта также создает частные, коммерческие и социальные риски, и начинает приниматься законодательство, ограничивающее эти риски, например, Закон ЕС об искусственном интеллекте. В задачу данной статьи входит глубокое изучение этих рисков, но стоит упомянуть лишь некоторые из них: существуют риски небезопасного, дискриминационного и нарушающего конфиденциальность поведения систем на базе искусственного интеллекта, а также интеллектуальной собственности, лицензирования и кибербезопасности. -риски безопасности.
Первым шагом в борьбе с этими рисками является знание того, какие технологии искусственного интеллекта используются в каждой системе; такие знания могут позволить заинтересованным сторонам управлять рисками (например, управлять юридическими рисками, зная лицензию на наборы данных и модели) и реагировать на новые данные, касающиеся этих технологий (например, если модель оказывается дискриминационной, заинтересованная сторона может сопоставить все системы, которые используют эту модель для снижения риска).
Взглянув на развивающееся регулирование, изучив Распоряжение 13960 «Содействие использованию заслуживающего доверия искусственного интеллекта в федеральном правительстве» раскрывает такие принципы, как подотчетность, прозрачность, ответственность, отслеживаемость и нормативный мониторинг – все из которых требуют понимания того, какие технологии искусственного интеллекта используются в каждой системе.
ML-BOM — это документация по технологиям искусственного интеллекта в продукте. CycloneDX, известный формат OWASP для SBOM версии 1.5 и выше, поддерживает его и теперь является стандартом для ML-BOM.
Создание ML-BOM является сложной задачей; существует множество способов представления моделей и наборов данных; Модели и наборы данных ИИ могут использоваться на лету, а решение о том, какие модели использовать, может приниматься программно, на лету, не оставляя следов для стандартных технологий анализа компонентов для их обнаружения. Помимо этих проблем, ИИ по-прежнему остается новой технологией, в отличие от зрелых менеджеров пакетов программного обеспечения. Таким образом, отрасль еще не до конца понимает потребности в ML-BOM.
В качестве отправной точки мы решили сосредоточиться на создании ML-BOM для проектов, использующих де-факто стандарт HuggingFace. HuggingFace — это «менеджер пакетов» для моделей и наборов данных искусственного интеллекта, который сопровождается популярными библиотеками Python. Ниже приведены несколько снимков SBOM, которые мы автоматически сгенерировали на основе такого продукта.
Представьте себе продукт, состоящий из множества компонентов, некоторые из них — модели машинного обучения. Компонент CycloneDX ниже описывает такую модель:
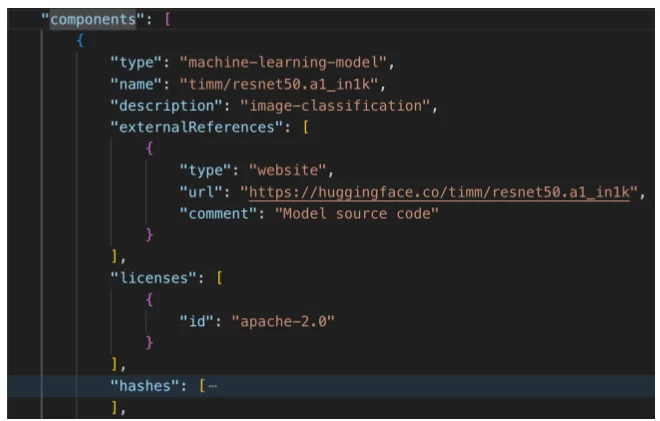
Компонент модели машинного обучения (часть 1) – стандартные данные компонента CycloneDX
Этот компонент идентифицирует модель и предоставляет ссылку для дальнейшего изучения информации об этой модели. Кроме того, он включает информацию о лицензировании, которую можно использовать в целях обеспечения соответствия.
CycloneDX V1.5 также определяет поле modelCard, специфичное для искусственного интеллекта, как стандартный способ документирования свойств модели машинного обучения. Ниже приведен пример созданной нами modelCard.
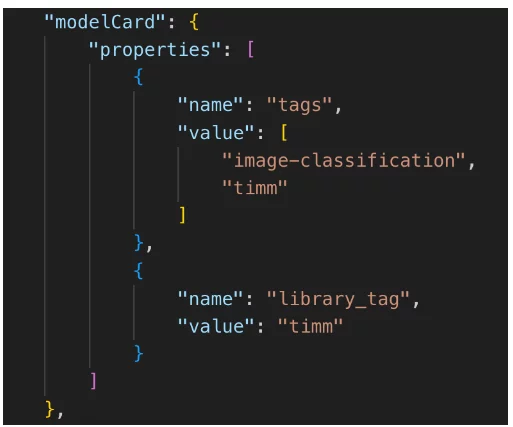
Компонент модели машинного обучения (часть 2) – карта данных
Вариантом использования такой modelCard может быть поиск всех продуктов, использующих модели классификации изображений, или запуск политики, запрещающей использование определенных типов моделей.
CycloneDX позволяет документировать дерево компонентов – иерархию подкомпонентов. Поскольку HuggingFace, как менеджер пакетов ИИ, представляет модели и наборы данных ИИ в виде git-репозиториев, мы решили документировать файлы модели/набора данных ИИ как подкомпоненты компонента модели машинного обучения. Вот как это выглядит:
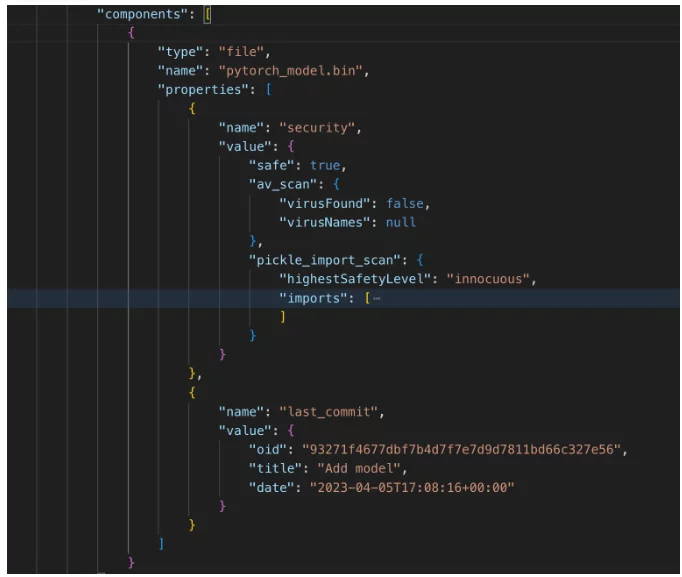
Компонент модели машинного обучения (часть 3) – подкомпоненты
Помимо стандартной информации о файле, свойства включают дополнительную информацию, например информацию о безопасности. В данном случае мы видим две меры безопасности:
- Сканирование на вирусы — важно при использовании наборов данных, подверженных вирусам (например, изображений, PDF-файлов и исполняемых файлов).
- Сканирование Pickle – меры безопасности в отношении файлов наборов данных типа «pickle», которые более подвержены риску (чтобы понять риски в этом формате, см. объяснение на странице Веб-сайт HuggingFace).
Эти данные можно использовать для применения политик, проверяющих успешность сканирования на наличие вирусов и рассолений.
ML-BOM — это новая концепция; то, что мы показываем здесь, является первым шагом. Но даже в этом случае мы можем понять, какую ценность это принесет, учитывая растущее внедрение, регулирование и риски ИИ.
В заключение я попросил свой хрустальный шар (он же ChatGPT) описать будущее ML-BOM, и вот его ответ:
«В не столь отдаленном будущем ML-BOM могут просто превратиться в кибер-подкованных, автопилотирующих маэстро, организующих симфонию моделей машинного обучения с чутьем автоматизации, и все это время танцуя чечетку через тонкости конвейеров CI/CD. ».
Что ж, возможно, нам нужно нечто большее, чем просто ML-BOM…
Этот контент предоставлен вам Scribe Security, ведущим поставщиком комплексных решений для обеспечения безопасности цепочки поставок программного обеспечения, обеспечивающим современную безопасность артефактов кода, а также процессов разработки и доставки кода по всей цепочке поставок программного обеспечения. Подробнее.
Статьи по теме


