CVE (Häufige Schwachstellen und Gefährdungen)-Scans sind für die Sicherung Ihrer Softwareanwendungen unerlässlich. Angesichts der zunehmenden Komplexität von Software-Stacks kann es jedoch eine Herausforderung sein, alle CVEs zu identifizieren und anzugehen. Eines der größten Probleme bei CVE-Scans ist heute die Verbreitung falsch positiver Ergebnisse, bei denen eine Schwachstelle in einem Paket identifiziert wird, das in der Produktionsanwendung nicht verwendet wird.
Es ist wichtig zu bedenken, dass selbst wenn Sie eine vollständige Liste aller Ihrer Softwarepakete und eine vollständige Liste aller in diesen Paketen enthaltenen CVEs haben, ziemlich sicher ist, dass nicht alle davon für Ihre Anwendung relevant sind. Das CVE befindet sich möglicherweise in einer Funktion, die in Ihrem Code nicht verwendet wird, oder in einem Teil der Bibliothek, den Sie nicht einmal aufrufen. Möglicherweise handelt es sich um eine vorübergehende Abhängigkeit, die nur aufgrund einer ungepatchten Abhängigkeitsliste aufgerufen wird und in Ihrem Code überhaupt nicht verwendet wird. Selbst wenn Sie wissen, dass sich ein CVE in einem Teil einer von Ihnen verwendeten Bibliothek befindet, gibt es keine Garantie dafür, dass das CVE tatsächlich in Ihrer Anwendung ausgenutzt werden kann. Einige Exploits erfordern extreme Bedingungen, um von Hackern genutzt werden zu können, darunter die Kombination von drei oder mehr CVEs in Folge, der richtige Stack und die richtige Infrastruktur. Da Sie sich jedes CVE, das Sie bei Ihrem Scan erhalten, noch genauer ansehen müssen, wird Ihnen klar, wie wichtig es ist, die Anzahl der CVEs, die Sie erhalten, zu reduzieren, damit Sie nicht unter Alarmmüdigkeit oder CVE-Burnout leiden, bevor Sie zurückkommen können um tatsächlich die nächsten Funktionen Ihrer Anwendung zu erstellen.
In diesem Artikel stelle ich einige mögliche Lösungen zur Reduzierung falsch positiver Ergebnisse bei CVE-Scans vor, mit dem Ziel, die Gesamtzahl der CVEs zu reduzieren, mit denen Sie umgehen müssen. Ich bespreche zunächst die Herausforderungen bei der Identifizierung von Paketen und stelle dann eine Datenbank vor, die Paketdateien Paketnamen zuordnet. Außerdem werde ich auf Scoping- und Codepfadprobleme eingehen, die zu Fehlalarmen führen können.
Schauen wir uns zunächst an, wie CVEs überhaupt identifiziert werden.
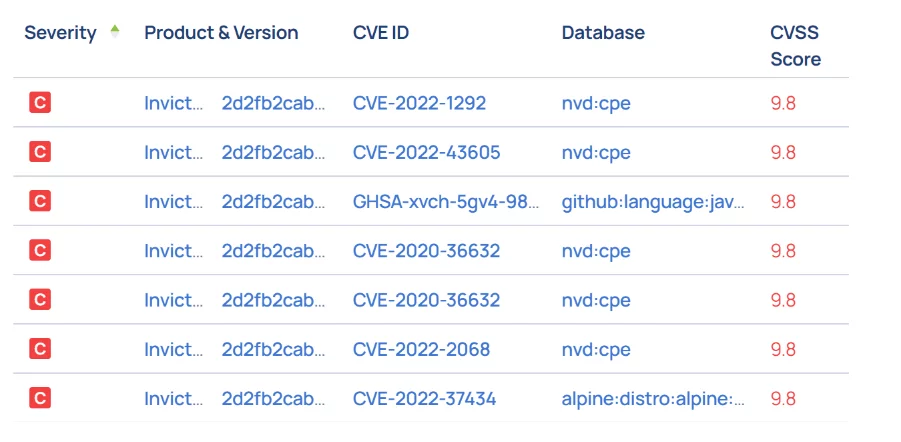
Das Mystery-Paket und das fehlende CVE
Die Mitre Corporation ist eine amerikanische gemeinnützige Organisation, die für die zuständig ist CVE®-Programm. Die Programme Die Mission besteht darin, öffentlich bekannt gegebene Cybersicherheitslücken zu identifizieren, zu definieren und zu katalogisieren. Dies funktioniert so, dass Sie, sobald Sie eine Schwachstelle gefunden haben, ein Formular ausfüllen und, wenn der Fund bestätigt werden kann, der Schwachstelle eine neue CVE-Kennung zugewiesen und sie der öffentlichen CVE-Datenbank hinzugefügt wird.
Angesichts der Art und Weise, wie CVEs aufgelistet werden, besteht eine der größten Herausforderungen bei CVE-Scans darin, Pakete und Bibliotheken korrekt zu identifizieren. Wenn jemand eine Schwachstelle in einem Paket oder einer Bibliothek identifiziert, listet er sie mit dem Paketnamen und der Version auf, mit der er vertraut ist. Natürlich verwenden nicht alle Tools die gleichen Namenskonventionen und für Paketnamen gibt es keinen globalen Standard. Das „Namensproblem“, wie es genannt wird, ist so schwerwiegend, dass mehrere Foren und Denkgruppen seit langem versuchen, eine gemeinsame Lösung zu finden. Als Beispiel hier OWASPs vorgeschlagene Lösung für das Problem, wie es mit der Erstellung von zusammenhängt SBOMs. Häufig verlassen sich Scan-Tools hinsichtlich der Paketnamen, die sie im Scan-Ergebnis liefern, auf die ihnen zugeführten Quellen, wie z. B. erstellte oder kompilierte Artefakte, und diese Quellen sind nicht immer zuverlässig. Verpackungen und Anpassungen können beispielsweise die Identifizierung der tatsächlichen Verpackung erschweren. Darüber hinaus hinterlassen einige Paketdateien möglicherweise keine Spuren ihres Installationspakets, z. B. Docker-COPY-Befehle.
Um diese Probleme anzugehen, haben wir bei Scribe-Sicherheit, schlagen Sie vor, eine Datenbank für Ihre Anwendung zu erstellen, die Paketdateien Paketnamen zuordnet. Selbst wenn der Paketname unterschiedlich ist, wären die Dateien und die Datei-Hashes identisch, wenn es sich um dasselbe Paket handelt. Auf diese Weise können Sie Probleme mit Wrappern und Anpassungen überspringen und das eigentliche Paket identifizieren, das behoben werden muss. Dieser Ansatz kann beim CVE-Behebungsprozess Zeit und Aufwand sparen. Seit der Scribe-Plattform Wenn Sie bereits die Dateien identifizieren, die mit jedem in Ihrem endgültigen Bild enthaltenen Paket verknüpft sind, ist die Erstellung einer solchen Datenbank der nächste logische Schritt. Wir beabsichtigen, dass sich unser CVE-Scan nicht auf den vom CVE aufgeführten Namen und die Version stützen muss, sondern auf die tatsächlichen Dateien, die das Paket enthält.
Bist du meine Mutter?
Beim Umgang mit einem endgültigen Build, bei dem es sich um ein Docker-Image handelt, ist es heutzutage üblich, nicht bei Null anzufangen. Mit einem soliden Ausgangspunkt, beispielsweise einem etablierten Basis-Image, können sich Entwickler auf den Teil des Builds konzentrieren, der ihre Anwendung darstellt, anstatt mit der Planung der Umgebung zu beginnen, in der sie ausgeführt werden muss. Eine der Herausforderungen bei der Verwendung von Docker-Images besteht darin, deren Herkunft und Abhängigkeiten zu verstehen, insbesondere wenn es um das übergeordnete Image (außer dem Basis-Image) geht, auf dem das endgültige Image erstellt wird.
Das übergeordnete Image ist ein Konzept, das wir uns ausgedacht haben, um den nächsten „lebenden Verwandten“ eines Docker-Images zu erklären. Bilder werden in unterschiedlichen Schichten erstellt. Nehmen wir also an, ich verwende ein bekanntes Basisbild wie Alpine, Debian oder Ubuntu und baue meine Anwendungsschicht direkt darauf auf. In diesem Fall wäre mein nächstgelegenes „Elternteil“ dieses Basis-Image. Aber was ist, wenn das Unternehmen, für das ich arbeite, einen anderen Ausgangspunkt hat, der ein Basis-Image und einige weitere Ebenen zusätzlich zu den Sicherheitstools umfasst, die für alle Unternehmens-Images obligatorisch sind? In diesem Fall wäre mein übergeordnetes Bild diese Unternehmensvorlage und ich könnte auch das Basisbild identifizieren, auf dem diese Vorlage aufbaut.
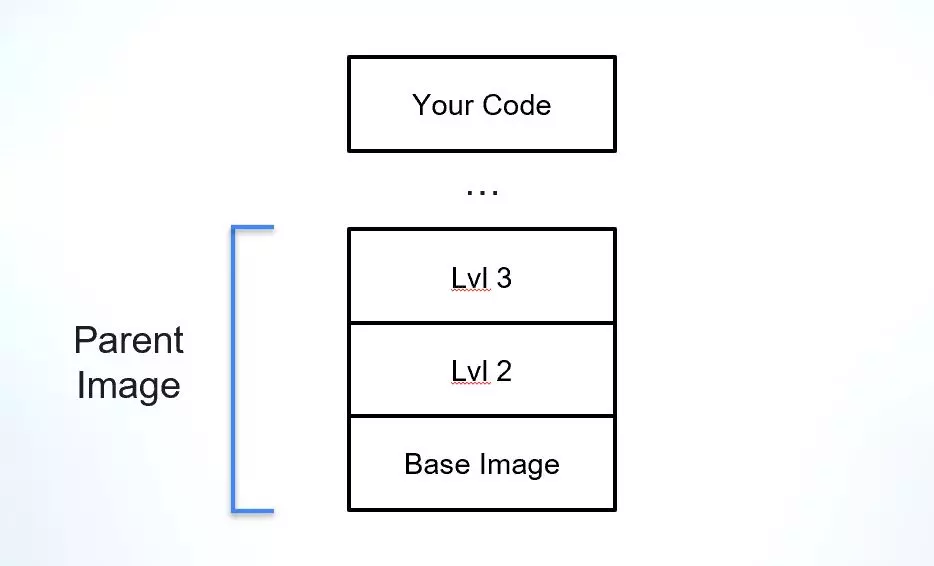
Das übergeordnete Image ist ein entscheidender Teil Ihrer Software-Lieferkette, da es die Grundlage für die Anwendung und ihre Abhängigkeiten bildet. Docker-Images enthalten nativ nicht viele Informationen über die Herkunft ihrer übergeordneten oder Basis-Images, was es schwierig macht, ihre Integrität zu überprüfen, ihre Schwachstellen zu verstehen und ihre Lizenz zu verifizieren.
Um dieses Problem anzugehen, hat Scribe ein Open-Source-Tool und einen Open-Source-Dienst namens entwickelt ParentImage um das nächstgelegene gescannte übergeordnete Element eines Docker-Images zu erkennen. Dieses Tool kann verwendet werden, um das übergeordnete Image eines Docker-Images zu identifizieren, was eine wichtige Möglichkeit zur Risikominderung darstellt:
Erstens kann man durch die Identifizierung des Basis-Images dessen Integrität überprüfen und sicherstellen, dass es nicht manipuliert oder kompromittiert wurde. Dies ist wichtig für die Aufrechterhaltung der Sicherheit und Stabilität der Anwendung.
Zweitens kann man Schwachstellen effektiver priorisieren und verwalten, indem man versteht, welche Schwachstellen aus dem übergeordneten Image und welche aus der Anwendungsschicht selbst stammen. Dies bedeutet, dass CVEs, die mit Ihrem Basis-Image oder Ihrem übergeordneten Image verknüpft sind, im Vergleich zu CVEs in der Anwendungsschicht weniger dringend sind (und nicht immer in Ihrer Verantwortung für die Behebung liegt).
Darüber hinaus kann durch die Identifizierung des übergeordneten Bildes dessen Lizenz überprüft und die Einhaltung gesetzlicher und interner Richtlinienanforderungen sichergestellt werden.
Das Open-Source-Tool ParentImage enthält eine aktualisierbare Datenbank mit Docker-Image-Scans. Sie können es teilen und vollständig intern verwenden, aber wir hoffen, dass die Leute ihre Docker-Images scannen und uns diese Informationen senden, damit sie in die Datenbank aufgenommen werden. Je mehr Bildscans die Datenbank enthält, desto mehr „Eltern“ kann das Tool identifizieren. Derzeit verfügt die mitgelieferte Datenbank über eine vollständige Liste aller etablierten Basisbilder als Proof of Concept. Da es sich um ein Open-Source-Tool handelt, kostet es nichts, es auszuprobieren. Wenn Sie also Docker-Images verwenden, empfehle ich Ihnen, dieses Tool als mögliche Lösung für einen Grund für nicht verwandte CVEs in Betracht zu ziehen.
Soll ich scannen oder überspringen?
Eine weitere Herausforderung bei CVE-Scans sind Scoping-Probleme. Der Umfang bezieht sich auf den Speicherort der gescannten Dateien und Pakete – was in den Scan einbezogen werden soll und was getrost ignoriert werden kann. Manchmal wird ein CVE in einem Paket gefunden, das in der Produktionsversion der Anwendung nicht tatsächlich verwendet wird. Beispielsweise kann ein Paket aufgrund einer indirekten Abhängigkeit von einem Test-Framework installiert werden. Um dieses Problem zu lösen, müssen Scanner den Umfang der Anwendungsdateien bewerten und die verwendeten indirekten Abhängigkeiten identifizieren.
OWASP-Plugins (The Open Worldwide Application Security Project) enthalten einige gute Beispiele für Tools, die bei Scoping-Problemen helfen können. OWASP-Abhängigkeits-Checkkann beispielsweise die Abhängigkeiten einer Anwendung analysieren und CVEs im Kontext des Abhängigkeitsdiagramms der Anwendung identifizieren. Auf diese Weise kann festgestellt werden, welche CVEs in der Produktionsanwendung verwendet werden und welche nicht.
Was auch immer die Zahl sein mag, Sie müssen sich trotzdem um Ihre CVEs kümmern
Da es kein anderes Tool gibt, das Ihnen sagen könnte, wo Ihre Anwendung anfällig für mögliche Hacks, Hintertüren und andere Probleme dieser Art ist, ist ein CVE-Scan immer noch eine ziemlich einfache Option, um potenzielle Probleme zu beheben. Das Problem besteht darin, dass, bis Sie überprüfen, ob ein CVE, das Ihnen im Scan präsentiert wird, ein tatsächliches Problem darstellt, es eine Bedrohung darstellt, die von Aufsichtsbehörden, Dritten und Benutzern gleichermaßen gegen Sie verwendet werden kann.
Im Namen der Sicherheit und Transparenz müssen Sie jedes potenzielle Problem durchgehen und beweisen, dass es entweder kein Problem ist, für Ihre Anwendung nicht relevant ist oder dass es sich um ein potenzielles Problem handelt und Sie daran arbeiten, es zu beheben. Die Tatsache, dass viele dieser CVEs aus externen, meist Open-Source-Paketen in Ihre Anwendung gelangen, bedeutet, dass Sie selbst dann, wenn Sie sie als potenziellen Exploit identifizieren, wahrscheinlich immer noch die Hilfe der Paketbetreuer benötigen, um sie zu patchen.
Bei all dieser Arbeit, die mit jedem CVE verbunden ist, ist es kein Wunder, dass Sie bei Ihrem nächsten CVE-Scan lieber eine möglichst kleine Zahl erhalten möchten. Die Verwendung einiger der in diesem Artikel dargelegten Vorschläge könnte dazu beitragen, die gewaltige Aufgabe, Ihre Schwachstellen zu beheben, ein wenig leichter zu bewältigen.
Wenn Sie andere Open-Source- oder kostenlose Tools zur Lösung des Problems haben, würden wir uns freuen, davon zu hören. Erzählen Sie uns davon in den Kommentaren und teilen Sie der Community mit, wie Sie mit Ihrem Berg an Schwachstellen umgehen.

Diese Inhalte werden Ihnen von Scribe Security zur Verfügung gestellt, einem führenden Anbieter von End-to-End-Sicherheitslösungen für die Software-Lieferkette, der modernste Sicherheit für Code-Artefakte sowie Code-Entwicklungs- und Bereitstellungsprozesse in der gesamten Software-Lieferkette bietet. Weitere Informationen.
Ähnliche Artikel