Die Sicherung Ihrer Software-Lieferkette beginnt mit der Entdeckung und Verwaltung Ihrer „Softwarefabrik“.
In der heutigen Softwareentwicklungsumgebung verwalten Teams dezentrale Assets wie Code-Repositories, Build-Pipelines und Container-Images. Dieses verteilte Modell bietet zwar Flexibilität und beschleunigt die Produktion, fragmentiert jedoch auch die Assets und erschwert die Governance und Sicherheitsüberwachung, insbesondere da Cloud-native Anwendungen immer weiter verbreitet sind.
Infolgedessen verlieren Sicherheitsteams häufig wertvolle Zeit bei der Suche nach Codebesitzern für verwaiste Produktionsworkloads, wenn Sicherheitsprobleme auftreten oder nicht genehmigte Softwareartefakte in die Produktion gelangen. Die Softwarelieferkette ist zu einer kritischen Angriffsfläche geworden, und es ist wichtig, Sicherheitssignale frühzeitig zu erfassen – von der Entwicklung bis hin zur Erstellungsphase –, um blinde Flecken zu vermeiden und sicherzustellen, dass alle Assets über den gesamten Softwareentwicklungslebenszyklus (SDLC) hinweg überwacht werden.
DevSecOps-Teams verfügen in der Regel nicht über automatisierte Tools, um diese sich verändernde Entwicklungslandschaft, in der häufig neue Codepfade und Tools eingeführt werden, kontinuierlich abzubilden. Informationen bleiben oft auf verschiedenen Plattformen isoliert, was den Zugriff aus Sicherheitsgründen erschwert. Entwicklungsplattformen und -tools variieren häufig während der Entwicklung, Integration und Bereitstellung, während die Software die verschiedenen Phasen durchläuft.
Während Anbieter von Application Security Posture Management (ASPM) und Observability Sicherheitsscans aggregieren, gelingt es ihnen häufig nicht, eine vollständige Ansicht bereitzustellen, die die Codepfade mit der Produktion verbindet.
Das Vorhandensein veralteter Assets verschärft das Problem. Die Identifizierung der noch in der Produktion aktiven Repositories kann insbesondere für große Organisationen eine Herausforderung sein. Fusionen und Übernahmen erschweren dies zusätzlich, da unterschiedliche Plattformen und Entwicklungsstandards hinzukommen.
DevSecOps-Teams greifen häufig auf manuelle Prozesse zurück – wie das Ausfüllen von Manifesten oder das Beschriften von Containern – die mühsam und fehleranfällig sind und häufig zugunsten dringenderer Prioritäten vernachlässigt werden.
Stellen Sie es sich vor wie die Verteidigung eines sich ständig verändernden Schlachtfelds, bei dem Sicherheitsteams eine genaue Karte benötigen, um ihre Vermögenswerte zu schützen. Diese Vermögenswerte entwickeln sich ständig weiter und neue Ziele müssen identifiziert und gesichert werden. Um dies zu erreichen, ist ein kontinuierlicher Erkennungsmechanismus erforderlich, um Änderungen abzubilden, sobald sie auftreten.
Best Practices und Frameworks unterstützen diesen Ansatz. So Agentur für Cybersicherheit und Infrastruktursicherheit (CISA) verpflichtet Organisationen, die Herkunft von Softwarekomponenten zu überprüfen und ein umfassendes Inventar als Teil ihrer Selbstbescheinigungsprozess. Ähnlich, die NIST-Framework für sichere Softwareentwicklung (SSDF) und der OWASP DevSecOps Reifegradmodell (DSOMM) betonen Sie die Bedeutung kontinuierlicher Entdeckung und Sichtbarkeit.
Im weiteren Verlauf dieses Beitrags skizzieren wir einen Plan zur Bewältigung dieser Herausforderungen und untersuchen, wie Scribe Security Unternehmen bei der wirksamen Implementierung dieser Funktionen unterstützt.
Scribes Blaupause für effektive Entdeckung
Discovery generiert eine in einem Diagramm modellierte Karte, die einen Überblick über Anlagen, Beziehungen und die Sicherheitslage Ihrer Fabrik bietet. Dies ermöglicht:
- Vollständige Transparenz und Eigentumskontrolle.
- Erweiterte Abfragefunktionen.
- Überwachung von KPIs und Sicherheitsreifemetriken.
- Schnellere Identifizierung und Priorisierung von Risikofaktoren.
- Erster Scan
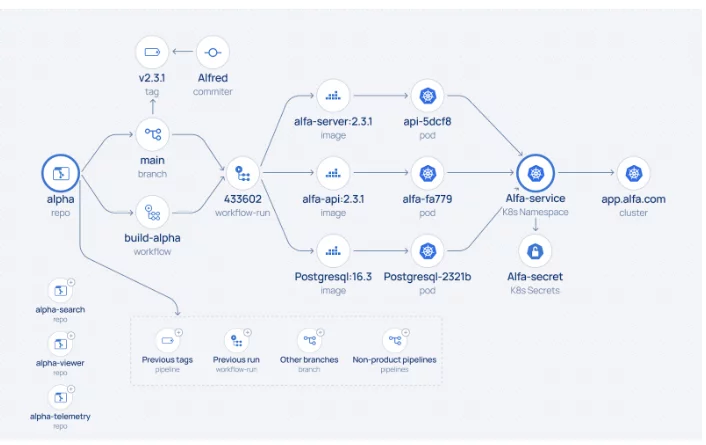
Der erste Scan zielt darauf ab, eine Übersicht über die Assets zu erstellen und sich auf die Identifizierung der Assets zu konzentrieren, die einer weiteren Analyse bedürfen. Ein vollständiger Tiefenscan kann zeitaufwändig sein und viele Assets, z. B. solche, die nicht mit der Produktion verknüpft oder veraltet sind, sind möglicherweise irrelevant. Dieser erste Scan erfasst normalerweise grundlegende Details wie Repository-Namen, IDs und Aktivitätsstatistiken, enthält jedoch keine vollständige Liste der Commits oder Mitwirkenden.
Eine Methode ist das Scannen von „rechts nach links“. Durch den Zugriff auf Produktionsumgebungen (z. B. über die K8s-Cluster-API) kann der Scanner laufende Container-Images identifizieren – kritische Assets, die den Geschäftswert widerspiegeln. Von dort aus verfolgt der Scan zurück zum Container-Register und den relevanten Repositories. Der Scan wird normalerweise hier angehalten, da normalerweise keine direkte Verbindung zwischen dem Register und der vorhergehenden SDLC-Pipeline besteht.
Ergänzende Scans können von „links nach rechts“ ausgeführt werden, um Code-Repositories, Build-Pipelines und Register in verschiedenen SDLC-Phasen (z. B. Entwicklung, Integration, Test) zu identifizieren.
Das Ergebnis ist eine priorisierte Liste von Assets auf allen Plattformen, die für eine gründliche Überprüfung bereit ist, um die Herkunft vom Code bis zur Produktion nachzuverfolgen und die Sicherheitslage des SDLC zu bewerten. Die Priorisierung basiert auf Faktoren wie Relevanz für die Produktion, Aktivitätsniveau und Aktualität. Manchmal hilft institutionelles Wissen über die Bedeutung von Assets bei der Steuerung dieses Prozesses.
Der erste Scan kann regelmäßig geplant oder durch Ereignisse wie Code-Pushes ausgelöst werden. Nachfolgende Scans können automatische Auswahlkriterien anwenden, z. B. die Verwendung von Globs für das gründliche Scannen neu entdeckter Assets.
- Tiefen-Scan
Sobald relevante Assets priorisiert sind, sammelt der Deep Scan detaillierte Attribute, die Beziehungen zwischen Assets herstellen, wie z. B. Branch-IDs, Commit- und Committer-IDs und Pipeline-Run-IDs. Die Dauer dieses Scans kann je nach Umfang der Assets und API-Ratenlimits variieren.
Am Ende dieser Phase nimmt ein Asset-Beziehungsdiagramm Gestalt an, mit Clustern verbundener Assets rund um Code-Repositorys (mit Build-Informationen) und Laufzeitumgebungen (mit Registry-Assets). Eine vollständige Herkunft ist jedoch immer noch unvollständig, da Registrys normalerweise keine Informationen über die Pipelines speichern, die die Build-Artefakte gepusht haben.
- Verbinden der Cluster
Sobald das Inventar erstellt ist, kann die Herkunft vervollständigt werden, indem ein CLI-Tool in der Pipeline instrumentiert wird, um Details zur Build-Herkunft zu erfassen, oder indem CI-Protokolle verarbeitet werden. Die Instrumentierung ist die zuverlässigste Methode, da sie wichtige Attribute wie Code-Repository-IDs, Pipeline- und Run-IDs sowie Image-IDs aufzeichnet. Sie verknüpft zuvor isolierte Cluster effektiv und erstellt eine vollständige End-to-End-Herkunft vom Code bis zur Produktion.
Ein ergänzender Ansatz ist die CI-Protokollverarbeitung, die relevante Attribute abruft, aber mehr Ressourcen erfordert und auf vorhandene Protokolle angewiesen ist. Diese Methode bietet zwar eine schnellere Implementierung, aber die besten Ergebnisse erzielt man, wenn man beide Ansätze kombiniert – kritische Pipelines instrumentieren und Protokollanalysen für neu entdeckte Pipelines verwenden, die dann für weitere Instrumentierungen ausgewertet werden können.
Dieser Clusteransatz berücksichtigt auch die Zusammenführung separater Linien in einer einheitlichen Struktur für komplexe Produkte, wie etwa aus mehreren Komponenten bestehende Webanwendungen, etwa Microservices.
- Software-Stückliste (SBOM)
Bisher lag der Schwerpunkt auf der plattformübergreifenden Verbindung von Entwicklungsressourcen, um eine klare Abstammung vom Code zur Produktion für relevante Ressourcen zu etablieren. Jetzt richtet sich die Aufmerksamkeit auf die Zusammensetzung der Softwareartefakte selbst. In diesem Schritt wird aus diesen Artefakten und den zugehörigen Code-Repositories ein SBOM generiert und dem vorhandenen Bestand hinzugefügt.
Durch die Synthese eines Code-Repositorys und von Artefakt-SBOMs zu einem einzigen SBOM mit einer Logik zum Korrelieren von Abhängigkeiten und Ausschließen irrelevanter Abhängigkeiten (wie etwa Entwicklungs- und Testbibliotheken) ist das Ergebnis ein genaueres und umfassenderes SBOM, als jede Quelle allein liefern könnte.
- Sicherheitslage und DevSecOPs-KPIs
Die kontinuierliche Abbildung des Asset-Inventars und seiner Beziehungen bietet die beste Möglichkeit, die Sicherheitslage dieser Assets zu beurteilen. Zu den wichtigsten Faktoren gehören Zugriffsberechtigungen für menschliche und nicht-menschliche Identitäten, die Überprüfung der Codesignatur, riskante oder anfällige Abhängigkeiten sowie Sicherheitseinstellungen über verschiedene Plattformen und Konten hinweg.
Diese Daten können in verschiedene Dimensionen aggregiert werden, um KPIs für Produktveröffentlichungen, Bereitstellungszeiten bis zur Produktion und DevSecOps-Reife zu messen. Insbesondere können Teams damit die Einführung von Sicherheitskontrollen wie Codesignierung und Einhaltung von Sicherheitseinstellungen bewerten, um den Fortschritt zu verfolgen und robuste Sicherheitspraktiken sicherzustellen.
- Visualisierung und Abfrage des SDLC- und Software-Supply-Chain-Diagramms
Ein wesentlicher Vorteil des Discovery-Prozesses ist die Möglichkeit, den SDLC und die Software-Lieferkette als dynamisches Diagramm oder „Schlachtkarte“ zu visualisieren. Diese Visualisierung bietet einen umfassenden Überblick über den gesamten Entwicklungslebenszyklus und erleichtert die Nachverfolgung von Assets und deren Beziehungen.
Die wahre Stärke liegt in der Möglichkeit, den Graphen abzufragen. Dadurch können Teams kritische Fragen stellen, beispielsweise:
- „Welche Komponente hat während der Erstellung oder Bereitstellung eine Sicherheitsüberprüfung nicht bestanden?“
- „Welche Workloads in der Produktion sind verwaist?“
- „Wer hat die Änderung vorgenommen, die eine Sicherheitslücke verursacht hat?“
- „Wem gehört das Asset, das gepatcht werden muss?“
Durch die Abfrage der Herkunft können Teams die Grundursache von Problemen ermitteln, was ein klarer Vorteil gegenüber der manuellen Dokumentation ist. Manuell gepflegte Eigentumszuordnungen veralten schnell, was DevSecOps-Teams häufig zu ineffizienten Suchen nach den richtigen Stakeholdern führt. Im Gegensatz dazu stellt ein abfragbares Diagramm sicher, dass Eigentum und Verantwortlichkeit immer auf dem neuesten Stand sind, wodurch weniger Zeit mit der Suche nach der Verantwortung für Code oder Infrastruktur verschwendet wird.
- Bereitstellungsoptionen für Discovery-Tools
Organisationen haben unterschiedliche Anforderungen an die Bereitstellung von Discovery-Tools. Um die unterschiedlichen Sicherheitsanforderungen zu erfüllen, ist es wichtig, flexible Bereitstellungsoptionen anzubieten. Einige Teams bevorzugen den Fernzugriff über eine SaaS-Plattform, da dies die Verwaltung und Skalierung vereinfacht. Andererseits entscheiden sich Teams mit strengeren Sicherheitsprotokollen möglicherweise für die lokale Bereitstellung von Scannern, um eine strengere Kontrolle über vertrauliche Anmeldeinformationen wie API-Token für Entwicklungsplattformen zu behalten. Die Wahl zwischen SaaS und lokaler Bereitstellung hängt von Faktoren wie der Sicherheitslage der Organisation, den Compliance-Anforderungen und der Kontrolle über die Daten ab.
Fazit
Die Sicherung Ihrer Software-Lieferkette ist ein ständiger Kampf; kein Unternehmen sollte sich ohne klare Karte darauf einlassen. Durch die Implementierung eines robusten Erkennungsprozesses erhalten Sie umfassende Transparenz über Ihren SDLC und Ihre Lieferkette und stellen sicher, dass jedes Asset von der Entwicklung bis zur Produktion berücksichtigt wird. Mit Tools wie dem Blueprint von Scribe Security können Sie eine zusammenhängende Abstammungslinie erstellen, genaue SBOMs generieren, Ihre Sicherheitslage bewerten und kritische Beziehungen innerhalb Ihres Entwicklungsökosystems visualisieren. Diese Einblicke ermöglichen es DevSecOps-Teams, Schwachstellen schnell zu identifizieren, ihre Ursprünge zu verfolgen und ein aktuelles Verständnis ihrer Softwarelandschaft aufrechtzuerhalten – unerlässlich, um in der heutigen schnelllebigen und komplexen Entwicklungsumgebung die Nase vorn zu behalten.
Schreiber bietet eine umfassende Lösung für Discovery und Governance als wichtige Voraussetzung zur Sicherung Ihrer Software-Lieferkette:
- Erste und gründliche Scans – Identifiziert und priorisiert Assets wie Code-Repositories, Pipelines und Container-Images in allen Umgebungen und erstellt ein Inventar der relevanten Komponenten.
- Durchgängige Herkunft – Verbindet isolierte Asset-Cluster mithilfe von CLI-Tools und CI-Protokollen und bildet so eine vollständige Linie vom Code bis zur Produktion.
- Software-Stückliste (SBOM) – Generiert genaue SBOMs durch Synthese von Artefakt- und Repository-Daten und Ausschluss irrelevanter Abhängigkeiten.
- Bewertung der Sicherheitslage – Bewertet kontinuierlich Zugriffskontrollen, Codesignaturen und anfällige Abhängigkeiten, um Sicherheits-KPIs zu messen.
- Visualisierung und Abfrage – Visualisiert den gesamten SDLC und ermöglicht Abfragen zum Aufspüren von Schwachstellen, verwaisten Workloads und Asset-Eigentümerschaften.
- Flexible Bereitstellung – Unterstützt sowohl SaaS- als auch lokale Bereitstellungen, um unterschiedlichen Sicherheitsanforderungen gerecht zu werden und die Kontrolle über vertrauliche Daten zu gewährleisten.
Diese Inhalte werden Ihnen von Scribe Security zur Verfügung gestellt, einem führenden Anbieter von End-to-End-Sicherheitslösungen für die Software-Lieferkette, der modernste Sicherheit für Code-Artefakte sowie Code-Entwicklungs- und Bereitstellungsprozesse in der gesamten Software-Lieferkette bietet. Weitere Informationen.
Ähnliche Artikel


