La protezione della tua catena di fornitura software inizia con la scoperta e la governance della tua "fabbrica di software"
Nell'ambiente di sviluppo software odierno, i team gestiscono asset decentralizzati come repository di codice, pipeline di build e immagini di container. Mentre questo modello distribuito offre flessibilità e velocizza la produzione, frammenta anche gli asset e complica la governance e la supervisione della sicurezza, soprattutto man mano che le applicazioni cloud-native diventano più diffuse.
Di conseguenza, i team di sicurezza spesso perdono tempo prezioso nel rintracciare i proprietari del codice per carichi di lavoro di produzione orfani quando sorgono problemi di sicurezza o quando artefatti software non autorizzati arrivano in produzione. La supply chain del software è diventata una superficie di attacco critica ed è essenziale raccogliere segnali di sicurezza in anticipo, dalle fasi di sviluppo a quelle di compilazione, per evitare punti ciechi e garantire che tutte le risorse nel ciclo di vita dello sviluppo software (SDLC) siano monitorate.
I team DevSecOps in genere non dispongono di strumenti automatizzati per mappare continuamente questo panorama di sviluppo in continua evoluzione, in cui vengono introdotti frequentemente nuovi percorsi di codice e strumenti. Le informazioni rimangono spesso isolate su diverse piattaforme, rendendone difficile l'accesso per motivi di sicurezza. Le piattaforme e gli strumenti di sviluppo spesso variano durante lo sviluppo, l'integrazione e la distribuzione, man mano che il software viene promosso attraverso le fasi.
Sebbene i fornitori di ASPM (Application Security Posture Management) e di osservabilità aggreghino le scansioni di sicurezza, spesso non riescono a fornire una visione completa che colleghi i percorsi del codice alla produzione.
La presenza di asset obsoleti aggrava il problema. Identificare quali repository sono ancora attivi in produzione può essere arduo, in particolare per le grandi organizzazioni. Fusioni e acquisizioni complicano ulteriormente la situazione aggiungendo diverse piattaforme e standard di sviluppo.
I team DevSecOps ricorrono spesso a processi manuali, come la compilazione di manifesti o l'etichettatura di contenitori, che sono noiosi, soggetti a errori e spesso accantonati a favore di priorità più urgenti.
Immagina di dover difendere un campo di battaglia in continuo cambiamento, dove i team di sicurezza hanno bisogno di una mappa precisa per proteggere i propri asset. Questi asset sono in continuo movimento nello sviluppo e nuovi obiettivi devono essere identificati e protetti. Per risolvere questo problema, è necessario un meccanismo di scoperta continuo per mappare i cambiamenti man mano che si verificano.
Le best practice e i framework supportano questo approccio. Ad esempio, Agenzia per la sicurezza informatica e delle infrastrutture (CISA) impone alle organizzazioni di verificare la provenienza dei componenti software e di mantenere un inventario completo come parte del loro processo di autocertificazione. Allo stesso modo, il Framework di sviluppo software sicuro (SSDF) del NIST e la Modello di maturità OWASP DevSecOps (DSOMM) sottolineare l'importanza della scoperta e della visibilità continue.
Nel resto di questo post delineeremo un modello per affrontare queste sfide ed esploreremo il modo in cui Scribe Security aiuta le organizzazioni a implementare queste funzionalità in modo efficace.
Progetto di Scribe per una scoperta efficace
Discovery genera una mappa modellata in un grafico, che fornisce una vista di asset, relazioni e della postura di sicurezza della tua fabbrica. Ciò consente:
- Visibilità completa e controllo della proprietà.
- Funzionalità di query avanzate.
- Monitoraggio dei KPI e delle metriche di maturità della sicurezza.
- Identificazione più rapida e definizione delle priorità dei fattori di rischio.
- Scansione iniziale
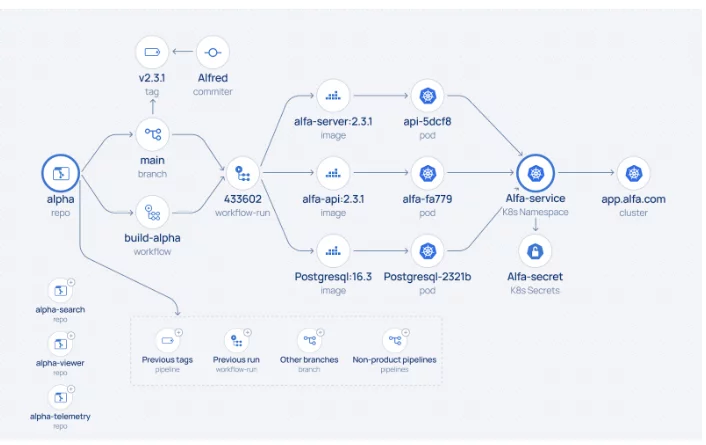
La scansione iniziale mira a creare una mappa di alto livello delle risorse, concentrandosi sull'identificazione di quelle che richiedono un'analisi più approfondita. Una scansione approfondita completa può richiedere molto tempo e molte risorse, come quelle non collegate alla produzione o obsolete, potrebbero essere irrilevanti. Questa scansione iniziale in genere raccoglie dettagli di base come nomi di repository, ID e statistiche di attività, ma non include un elenco completo di commit o contributori.
Un metodo è la scansione da "destra a sinistra". Accedendo agli ambienti di produzione (ad esempio, tramite l'API del cluster K8s), lo scanner può identificare le immagini dei container in esecuzione, asset critici che riflettono il valore aziendale. Da lì, la scansione risale al registro dei container e ai repository pertinenti. La scansione in genere si interrompe qui, poiché di solito non c'è una connessione diretta tra il registro e la pipeline SDLC precedente.
Le scansioni complementari possono essere eseguite da "sinistra a destra", identificando repository di codice, pipeline di build e registri nelle diverse fasi del ciclo di vita del software (ad esempio, sviluppo, integrazione, test).
Il risultato è un elenco prioritario di asset su tutte le piattaforme, pronto per una scansione approfondita per tracciare la discendenza dal codice alla produzione e valutare la postura di sicurezza dell'SDLC. La priorità si basa su fattori come la pertinenza alla produzione, il livello di attività e la recenza. A volte, la conoscenza istituzionale della significatività degli asset aiuta a guidare questo processo.
La scansione iniziale può essere programmata periodicamente o attivata da eventi come i push di codice. Le scansioni successive possono applicare criteri di selezione automatica, come l'utilizzo di glob per la scansione approfondita di asset appena scoperti.
- Scansione profonda
Una volta che le risorse rilevanti sono state prioritizzate, la scansione approfondita raccoglie attributi dettagliati che stabiliscono relazioni tra le risorse, come ID di branch, ID di commit e committer e ID di esecuzione della pipeline. La durata di questa scansione può variare a seconda dell'ambito delle risorse e dei limiti di velocità dell'API.
Alla fine di questa fase, un grafico delle relazioni tra asset inizia a prendere forma, con cluster di asset connessi attorno a repository di codice (contenenti informazioni di build) e ambienti di runtime (con asset di registro). Tuttavia, una discendenza completa è ancora incompleta, poiché i registri in genere non archiviano informazioni sulle pipeline che hanno spinto gli artefatti di build.
- Collegamento dei cluster
Una volta stabilito l'inventario, il lignaggio può essere completato strumentando uno strumento CLI nella pipeline per catturare i dettagli di provenienza della build o elaborando i log CI. La strumentazione è il metodo più affidabile, registrando attributi chiave come ID del repository di codice, ID di pipeline ed esecuzione e ID di immagine. Collega efficacemente cluster precedentemente isolati e crea un lignaggio end-to-end completo dal codice alla produzione.
Un approccio complementare è l'elaborazione del log CI, che recupera gli attributi rilevanti ma richiede più risorse e dipende dal logging esistente. Mentre questo metodo offre un'implementazione più rapida, la combinazione di entrambi gli approcci produce i risultati migliori: strumentazione delle pipeline critiche e utilizzo dell'analisi del log per quelle appena scoperte, che possono quindi essere valutate per ulteriore strumentazione.
Questo approccio di clustering considera anche l'aggregazione di linee di discendenza separate in una struttura unificata per prodotti complessi, come le applicazioni web composte da più componenti, come i microservizi.
- Distinta base software (SBOM)
Fino a questo punto, l'attenzione si è concentrata sulla connessione di asset di sviluppo tra piattaforme, stabilendo una chiara discendenza dal codice alla produzione per gli asset rilevanti. Ora, l'attenzione si sposta sulla composizione degli artefatti software stessi. In questa fase, viene generato uno SBOM da quegli artefatti e dai repository di codice associati, aggiungendoli all'inventario esistente.
Sintetizzando un repository di codice e SBOM di artefatti in un singolo SBOM, con una logica per correlare le dipendenze ed escludere quelle irrilevanti, come le librerie di sviluppo e di test, il risultato è uno SBOM più accurato e completo di quello che entrambe le fonti potrebbero fornire da sole.
- Posizione di sicurezza e KPI DevSecOPs
La mappatura continua dell'inventario delle risorse e delle loro relazioni offre la migliore opportunità per valutare la postura di sicurezza di queste risorse. I fattori chiave includono permessi di accesso per identità umane e non umane, verifica della firma del codice, dipendenze rischiose o vulnerabili e impostazioni di sicurezza su varie piattaforme e account.
Questi dati possono essere aggregati in diverse dimensioni per misurare i KPI per le release dei prodotti, i tempi di distribuzione in produzione e la maturità DevSecOps. In particolare, consentono ai team di valutare l'adozione di controlli di sicurezza, come la firma del codice e l'aderenza alle impostazioni di sicurezza, aiutando a monitorare i progressi e a garantire solide pratiche di sicurezza.
- Visualizzazione e interrogazione del grafico SDLC e della supply chain del software
Uno dei principali vantaggi del processo di scoperta è la possibilità di visualizzare l'SDLC e la supply chain del software come un grafico dinamico o "mappa di battaglia". Questa visualizzazione offre una visione completa dell'intero ciclo di vita dello sviluppo, semplificando il monitoraggio delle risorse e delle loro relazioni.
Il vero potere deriva dalla possibilità di interrogare il grafico, consentendo ai team di porre domande critiche, come:
- "Quale componente non ha superato un controllo di sicurezza durante la sua compilazione o distribuzione?"
- "Quali carichi di lavoro in produzione sono orfani?"
- "Chi ha apportato la modifica che ha introdotto una vulnerabilità?"
- "Chi possiede la risorsa che deve essere riparata?"
L'interrogazione del lignaggio aiuta i team a identificare la causa principale dei problemi, il che è un chiaro vantaggio rispetto alla documentazione manuale. Le mappature di proprietà gestite manualmente diventano rapidamente obsolete, spesso portando i team DevSecOps a ricerche inefficienti per gli stakeholder giusti. Al contrario, un grafico interrogabile garantisce che la proprietà e la responsabilità siano sempre aggiornate, riducendo il tempo sprecato nel rintracciare la responsabilità per il codice o l'infrastruttura.
- Opzioni di distribuzione per gli strumenti di scoperta
Le organizzazioni hanno esigenze diverse per l'implementazione di strumenti di discovery e offrire opzioni di implementazione flessibili è essenziale per soddisfare diversi requisiti di sicurezza. Alcuni team preferiscono l'accesso remoto tramite una piattaforma SaaS, semplificando la gestione e la scalabilità. D'altro canto, i team con protocolli di sicurezza più rigidi potrebbero scegliere l'implementazione dello scanner locale per mantenere un controllo più rigoroso sulle credenziali sensibili, come i token API della piattaforma di sviluppo. La scelta tra SaaS e implementazione locale dipende da fattori come la postura di sicurezza dell'organizzazione, le esigenze di conformità e il controllo sui dati.
Conclusione
Proteggere la tua supply chain software è una battaglia continua; nessuna organizzazione dovrebbe affrontarla senza una mappa chiara. Implementando un solido processo di discovery, ottieni una visibilità completa sul tuo SDLC e sulla supply chain, assicurandoti che ogni asset sia contabilizzato, dallo sviluppo alla produzione. Con strumenti come il blueprint di Scribe Security, puoi creare una discendenza connessa, generare SBOM accurati, valutare la tua postura di sicurezza e visualizzare relazioni critiche all'interno del tuo ecosistema di sviluppo. Questo livello di insight consente ai team DevSecOps di identificare rapidamente le vulnerabilità, tracciarne le origini e mantenere una comprensione aggiornata del loro panorama software, essenziale per rimanere al passo con l'attuale ambiente di sviluppo complesso e frenetico.
Scriba offre una soluzione completa per la scoperta e la governance come abilitatore critico per la protezione della tua catena di fornitura software:
- Scansioni iniziali e approfondite – Identifica e assegna priorità a risorse quali repository di codice, pipeline e immagini di contenitori in tutti gli ambienti, creando un inventario dei componenti rilevanti.
- Linea di discendenza end-to-end – Collega cluster di asset isolati utilizzando strumenti CLI e log CI, formando una discendenza completa dal codice alla produzione.
- Distinta base software (SBOM) – Genera SBOM accurati sintetizzando dati di artefatti e repository, escludendo le dipendenze irrilevanti.
- Valutazione della postura di sicurezza – Valuta costantemente i controlli di accesso, le firme del codice e le dipendenze vulnerabili per misurare i KPI di sicurezza.
- Visualizzazione e query – Visualizza l'intero SDLC e consente query per tracciare vulnerabilità, carichi di lavoro orfani e proprietà delle risorse.
- Modello flessibile – Supporta sia distribuzioni SaaS che locali per soddisfare le diverse esigenze di sicurezza e controllo sui dati sensibili.
Questo contenuto è offerto da Scribe Security, un fornitore leader di soluzioni di sicurezza end-to-end per la catena di fornitura di software, che offre sicurezza all'avanguardia per artefatti di codice e processi di sviluppo e distribuzione del codice attraverso le catene di fornitura di software. Per saperne di più.
Post Correlati


