CVE(共通の脆弱性および脆弱性) スキャンは、ソフトウェア アプリケーションを保護するために不可欠です。ただし、ソフトウェア スタックの複雑さが増すにつれて、すべての CVE を特定して対処することが困難になる場合があります。現在の CVE スキャンに関する最大の問題の 1 つは、運用アプリケーションで使用されていないパッケージで脆弱性が特定される誤検知の蔓延です。
すべてのソフトウェア パッケージの完全なリストと、それらのパッケージに含まれるすべての CVE の完全なリストを取得したとしても、そのすべてがアプリケーションに関連しているわけではないことは明らかであることを覚えておくことが重要です。 CVE は、コード内で使用されていない関数内にあるか、呼び出してもいないライブラリの一部内にある可能性があります。パッチが適用されていない依存関係リストによってのみ呼び出され、コード内でまったく使用されていない一時的な依存関係にある可能性があります。使用するライブラリの一部に CVE が含まれていることがわかったとしても、その CVE が実際にアプリケーションで悪用可能であるという保証はありません。一部のエクスプロイトは、連続する 3 つ以上の CVE、適切なスタック、適切なインフラストラクチャの組み合わせなど、ハッカーが使用できるようにするために極端な条件を必要とします。スキャンから得られる各 CVE をさらに詳しく調べる必要があるため、回復する前にアラート疲労や CVE バーンアウトが発生しないように、取得する CVE の数を絞り込むことがいかに重要であるかがわかります。アプリケーションの次の機能を実際に構築します。
この記事では、対処する必要がある CVE の全体的な数を減らすことを目的として、CVE スキャンでの誤検知を軽減するための考えられるソリューションをいくつか紹介します。まずパッケージを識別する際の課題について説明し、次にパッケージ ファイルをパッケージ名にマッピングするデータベースの紹介に進みます。また、誤検知を引き起こす可能性のあるスコープとコード パスの問題についても説明します。
まず、CVE がどのように識別されるのかを見てみましょう。
ミステリー パッケージと見つからない CVE
マイター コーポレーションは、 CVE®プログラム。プログラムの 使命は、公開されているサイバーセキュリティの脆弱性を特定し、定義し、カタログ化することです。この仕組みは、脆弱性を見つけたらフォームに記入し、その発見が裏付けられると、その脆弱性に新しい CVE 識別子が与えられ、パブリック CVE データベースに追加されます。
CVE がリストされる方法を考慮すると、CVE スキャンの主な課題の 1 つは、パッケージとライブラリを正しく識別することです。誰かがパッケージまたはライブラリの脆弱性を特定すると、よく知っているパッケージ名とバージョンとともにそれをリストします。もちろん、すべてのツールが同じ命名規則を使用しているわけではなく、パッケージ名には既存の世界標準はありません。知られるようになった「命名問題」は非常に深刻であるため、複数のフォーラムや思想団体が長い間、共通の解決策を見つけようと努めてきました。例として、次のとおりです OWASP が提案するソリューション の作成に関連する問題については、 SBOM。多くの場合、スキャン ツールは、スキャン結果で提供されるパッケージ名をビルドまたはコンパイルされたアーティファクトなど、供給されるソースに依存しますが、これらのソースは常に信頼できるとは限りません。たとえば、ラッパーや適応により、実際のパッケージを識別することが困難になる場合があります。さらに、Docker COPY コマンドなど、一部のパッケージ ファイルはインストーラー パッケージの痕跡を残さない場合があります。
これらの問題に対処するために、私たちは スクライブセキュリティ、パッケージ ファイルをパッケージ名にマップするアプリケーション用のデータベースを作成することをお勧めします。パッケージ名が異なっていても、同じパッケージであれば、ファイルとファイルのハッシュは同一になります。そうすることで、ラッパーや適応に関連する問題をスキップし、対処する必要がある実際のパッケージを特定できます。このアプローチにより、CVE 修復プロセスの時間と労力を節約できます。以来、 スクライブプラットフォーム 最終イメージに含まれる各パッケージに関連付けられたファイルはすでに特定されているため、そのようなデータベースを作成するのが次の論理的なステップです。 CVE スキャンでは、CVE にリストされている名前とバージョンに依存する必要はなく、パッケージに含まれる実際のファイルに依存する必要があると考えています。
あなたは私のママですか?
Docker イメージである最終ビルドを扱う場合、最近では最初から始めないのが一般的です。確立された基本イメージなど、しっかりとした開始点があると、開発者は、アプリケーションを実行する必要がある環境の計画を開始するのではなく、アプリケーションであるビルドの部分に集中できます。 Docker イメージを使用する際の課題の 1 つは、特に最終イメージがその上に構築される親イメージ (ベース イメージを除く) に関して、その来歴と依存関係を理解することです。
親イメージは、Docker イメージの最も近い「生きた親戚」を説明するために私たちが考えた概念です。イメージは個別のレイヤーで構築されるため、Alpine、Debian、Ubuntu などの既知の基本イメージを使用し、その上にアプリケーション層を構築するとします。この場合、最も近い「親」はその基本イメージになります。しかし、私が働いている会社が別の出発点を持っていて、基本イメージと、すべての企業イメージに必須のセキュリティ ツールのレイヤーをさらにいくつか含んでいる会社だったらどうなるでしょうか?この場合、親イメージはこの会社テンプレートとなり、このテンプレートが構築された基本イメージも識別できます。
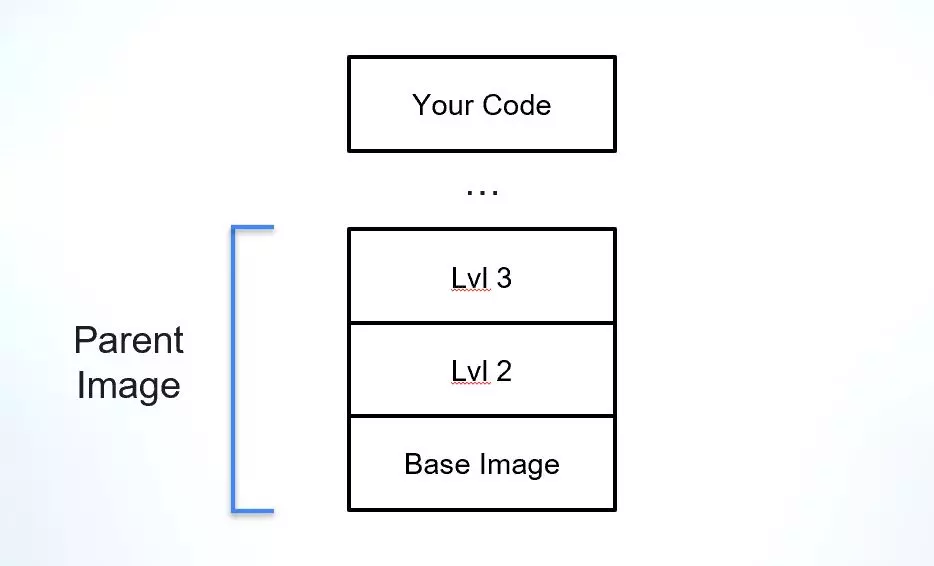
親イメージは、アプリケーションとその依存関係の基盤を提供するため、ソフトウェア サプライ チェーンの重要な部分です。本来、Docker イメージには親イメージや基本イメージの起源に関する情報があまり含まれていないため、その整合性の検証、脆弱性の理解、ライセンスの検証が困難になります。
この問題に対処するために、Scribe は、と呼ばれるオープンソース ツールとサービスを開発しました。 親画像 スキャンされた Docker イメージの最も近い親を検出します。このツールを使用すると、Docker イメージの親イメージを識別できます。これは、リスク軽減を可能にする重要な要素です。
まず、基本イメージを特定することで、その完全性を検証し、改ざんまたは侵害されていないことを確認できます。これは、アプリケーションのセキュリティと安定性を維持するために重要です。
次に、どの脆弱性が親イメージに由来し、どの脆弱性がアプリケーション層自体に由来するかを理解することで、脆弱性の優先順位を付け、より効果的に管理できるようになります。これは、ベース イメージまたは親イメージにリンクされている CVE は、アプリケーション層の CVE と比較した場合、緊急性が低い (修復する必要があるとは限りません) ことを意味します。
さらに、親イメージを識別することにより、そのライセンスを確認し、法的および内部ポリシーの要件への準拠を確認できます。
ParentImage オープンソース ツールには、Docker イメージ スキャンの更新可能なデータベースが含まれています。これをフォークして完全に内部で使用することもできますが、Docker イメージをスキャンして、その情報をデータベースに含めるために私たちに送ってほしいと考えています。データベースに含まれる画像スキャンの数が増えるほど、ツールが識別できる「親」の数も増えます。現在、付属のデータベースには、概念実証として確立されたすべての基本イメージの完全なリストが含まれています。オープンソース ツールなので、試すのに費用はかかりません。そのため、Docker イメージを使用している場合は、無関係な CVE の原因の 1 つに対する可能な解決策としてこのツールを検討することをお勧めします。
スキャンするべきですか、それともスキップすべきですか?
CVE スキャンに関するもう 1 つの課題は、スコープの問題です。スコープとは、スキャンされるファイルとパッケージの場所、つまりスキャンに含めるべきものと無視しても安全なものを指します。場合によっては、アプリケーションの実稼働バージョンでは実際には使用されていないパッケージ内で CVE が見つかることがあります。たとえば、パッケージは、一部のテスト フレームワークへの間接的な依存関係の結果としてインストールされる場合があります。これに対処するには、スキャナーはアプリケーション ファイルの範囲を評価し、使用されている間接的な依存関係を特定する必要があります。
OWASP (The Open Worldwide Application Security Project) プラグインには、スコープの問題に役立つツールの良い例がいくつかあります。 OWASP 依存関係チェックたとえば、アプリケーションの依存関係を分析し、アプリケーションの依存関係グラフのコンテキストで CVE を識別できます。これにより、実稼働アプリケーションでどの CVE が使用されているか、どの CVE が使用されていないかを識別できます。
数字が何であれ、CVE に対処する必要がある
アプリケーションのどこがハッキングやバックドアなどの潜在的な問題に対して脆弱であるかを知らせるツールが他にない場合でも、CVE スキャンは潜在的な問題に対処するための非常に基本的なオプションです。問題は、スキャンで提示された CVE が実際の問題であるかどうかを確認するまでは、それが規制当局、サードパーティ、ユーザーなどによって利用される可能性のある脅威であることです。
セキュリティと透明性の名の下に、潜在的な問題をすべて調査し、それが問題ではないこと、アプリケーションに関係がないこと、または潜在的な問題でありパッチの適用に取り組んでいることを証明する必要があります。これらの CVE の多くが外部の (通常はオープンソースの) パッケージからアプリケーションに入り込んでいるという事実は、たとえそれが潜在的なエクスプロイトであると特定したとしても、パッチを適用するにはパッケージ メンテナーの支援が必要になる可能性があることを意味します。
各 CVE に関連するこのすべての作業を考えると、次回の CVE スキャンではできるだけ小さい数値を取得したいと考えるのも不思議ではありません。この記事で概説したいくつかの提案を使用すると、脆弱性に対処するという大変な作業をもう少し管理しやすくなる可能性があります。
この問題に対処するための他のオープンソース ツールや無料ツールをお持ちの場合は、ぜひお知らせください。コメントでそのことについて教えていただき、山ほどある脆弱性にどのように対処しているかをコミュニティと共有してください。

このコンテンツは、エンドツーエンドのソフトウェア サプライ チェーン セキュリティ ソリューションの大手プロバイダーである Scribe Security によって提供されており、ソフトウェア サプライ チェーン全体のコード成果物とコード開発および配信プロセスに最先端のセキュリティを提供しています。 詳しくはこちら。
関連記事


