CVE (Vulnerabilidades y exposiciones comunes) los escaneos son esenciales para proteger sus aplicaciones de software. Sin embargo, con la creciente complejidad de las pilas de software, identificar y abordar todos los CVE puede resultar un desafío. Uno de los mayores problemas con los escaneos CVE hoy en día es la prevalencia de falsos positivos, donde se identifica una vulnerabilidad en un paquete que no está en uso en la aplicación de producción.
Es importante recordar que incluso una vez que tenga una lista completa de todos sus paquetes de software y una lista completa de todos los CVE que se encuentran en esos paquetes, es bastante seguro que no todos son relevantes para su aplicación. El CVE puede estar en una función que no está en uso en su código o en una parte de la biblioteca a la que ni siquiera llama. Podría estar en una dependencia transitoria a la que solo se llama debido a una lista de dependencias sin parches y que no se utiliza en absoluto en su código. Incluso una vez que sepa que un CVE se encuentra en una parte de una biblioteca que utiliza, no hay garantía de que el CVE sea realmente explotable en su aplicación. Algunos exploits requieren condiciones extremas para que los piratas informáticos puedan utilizarlos, incluida la combinación de 3 o más CVE en secuencia, la pila adecuada y la infraestructura adecuada. Dado que aún necesita observar más de cerca cada CVE que obtiene de su escaneo, puede ver lo importante que es reducir la cantidad de CVE que obtiene para no sufrir fatiga de alerta o agotamiento de CVE antes de poder regresar. para crear las próximas funciones de su aplicación.
En este artículo, ofreceré algunas posibles soluciones para mitigar los falsos positivos en los escaneos de CVE, con el objetivo de reducir la cantidad total de CVE con los que debe lidiar. Comenzaré analizando los desafíos de identificar paquetes y luego pasaré a presentar una base de datos que asigna archivos de paquetes a nombres de paquetes. También discutiré problemas de alcance y ruta de código que pueden causar falsos positivos.
Comencemos por ver cómo se identifican los CVE en primer lugar.
El paquete misterioso y el CVE perdido
La Mitre Corporation es una organización estadounidense sin fines de lucro que se encarga de la programa CVE®. Los programas La misión es identificar, definir y catalogar vulnerabilidades de ciberseguridad divulgadas públicamente. La forma en que esto funciona es que una vez que encuentra una vulnerabilidad, completa un formulario y, si se puede corroborar el hallazgo, se le asigna un nuevo identificador CVE a la vulnerabilidad y se agrega a la base de datos pública CVE.
Teniendo en cuenta la forma en que se enumeran los CVE, uno de los principales desafíos de los análisis de CVE es identificar paquetes y bibliotecas correctamente. Cuando alguien identifica una vulnerabilidad en un paquete o biblioteca, la enumera con el nombre del paquete y la versión con la que está familiarizado. Por supuesto, no todas las herramientas utilizan las mismas convenciones de nomenclatura y los nombres de los paquetes no tienen un estándar global existente. El 'Problema de los nombres', como se le conoce, es lo suficientemente grave como para que múltiples foros y grupos de expertos hayan estado tratando de encontrar una solución común durante mucho tiempo. Como ejemplo, aquí está La solución propuesta por OWASP para el problema en lo que se refiere a la creación de SBOM. A menudo, las herramientas de escaneo dependen de las fuentes que reciben, como artefactos creados o compilados, para los nombres de los paquetes que entregan en el resultado del escaneo y estas fuentes no siempre son confiables. Por ejemplo, los envoltorios y las adaptaciones pueden dificultar la identificación del paquete real. Además, es posible que algunos archivos de paquetes no dejen ningún rastro de su paquete de instalación, como los comandos COPY de Docker.
Para abordar estas cuestiones, nosotros, en Seguridad del escriba, sugiera crear una base de datos para su aplicación que asigne archivos de paquetes a nombres de paquetes. Incluso si el nombre del paquete es diferente, si es el mismo paquete, los archivos y los hashes de los archivos serán idénticos. Al hacerlo, puede omitir problemas relacionados con envoltorios y adaptaciones e identificar el paquete real que debe abordarse. Este enfoque puede ahorrar tiempo y esfuerzo en el proceso de corrección de CVE. desde el Plataforma de escriba ya está identificando los archivos asociados con cada paquete incluido en su imagen final, crear dicha base de datos es el siguiente paso lógico. Nuestra intención es que nuestro escaneo CVE no dependa del nombre y la versión enumerados en CVE, sino de los archivos reales que incluye el paquete.
¿Eres mi mami?
Cuando se trata de una compilación final que es una imagen de Docker, hoy en día es una práctica común no empezar desde cero. Tener un punto de partida sólido, como una imagen base establecida, permite a los desarrolladores centrarse en la parte de la compilación que es su aplicación en lugar de empezar a planificar el entorno en el que debe ejecutarse. Uno de los desafíos al usar imágenes de Docker es comprender su procedencia y dependencias, particularmente cuando se trata de la imagen principal (aparte de la imagen base) sobre la que se construye la imagen final.
La imagen principal es un concepto que se nos ocurrió para explicar el "pariente vivo" más cercano de una imagen de Docker. Las imágenes se crean en capas distintas, así que digamos que uso una imagen base conocida, como Alpine, Debian o Ubuntu, y construyo mi capa de aplicación justo encima de ella. En este caso, mi 'padre' más cercano sería esa imagen base. Pero, ¿qué pasa si la empresa para la que trabajo tiene un punto de partida diferente, uno que incluye una imagen base y algunas capas más además de las herramientas de seguridad que son obligatorias para todas las imágenes de la empresa? En este caso, mi imagen principal sería la plantilla de esta empresa y también podría identificar la imagen base sobre la que se creó esta plantilla.
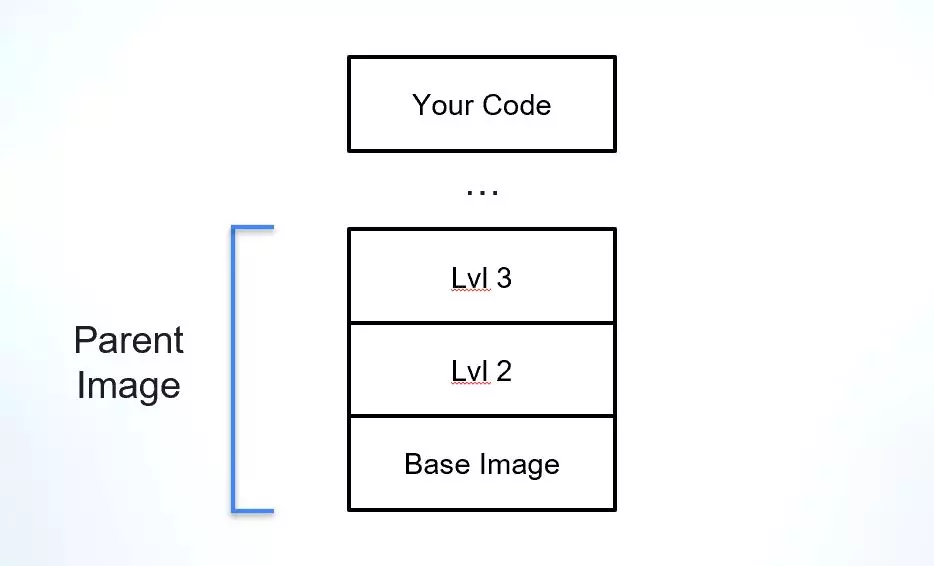
La imagen principal es una parte crucial de su cadena de suministro de software, ya que proporciona la base para la aplicación y sus dependencias. De forma nativa, las imágenes de Docker no incluyen mucha información sobre el origen de sus imágenes principales o base, lo que dificulta verificar su integridad, comprender sus vulnerabilidades y verificar su licencia.
Para abordar este problema, Scribe desarrolló una herramienta y un servicio de código abierto llamado Imagen principal para detectar el padre escaneado más cercano de una imagen de Docker. Esta herramienta se puede utilizar para identificar la imagen principal de una imagen de Docker, que es un factor clave para la reducción de riesgos:
Primero, al identificar la imagen base, se puede verificar su integridad y asegurarse de que no haya sido manipulada ni comprometida. Esto es importante para mantener la seguridad y estabilidad de la aplicación.
En segundo lugar, al comprender qué vulnerabilidades se originan en la imagen principal y cuáles en la propia capa de aplicación, se pueden priorizar y gestionar las vulnerabilidades de forma más eficaz. Esto significa que los CVE que están vinculados a su imagen base o a su imagen principal son menos urgentes (y no siempre es su responsabilidad corregirlos) en comparación con los CVE en la capa de aplicación.
Además, al identificar la imagen principal, se puede verificar su licencia y garantizar el cumplimiento de los requisitos legales y de políticas internas.
La herramienta de código abierto ParentImage incluye una base de datos actualizable de escaneos de imágenes de Docker. Puede bifurcarlo y usarlo completamente internamente, pero esperamos que las personas escaneen sus imágenes de Docker y nos envíen esa información para incluirla en la base de datos. Cuantos más escaneos de imágenes incluya la base de datos, más 'padres' podrá identificar la herramienta. Actualmente, la base de datos incluida tiene una lista completa de todas las imágenes base establecidas como prueba de concepto. Como herramienta de código abierto, no cuesta nada probarla, por lo que si está utilizando imágenes de Docker, le recomiendo que considere esta herramienta como una posible solución a un motivo de CVE no relacionados.
¿Debo escanear o debo omitir?
Otro desafío con los escaneos CVE son los problemas de alcance. El alcance se refiere a la ubicación de los archivos y paquetes analizados: qué se debe incluir en el análisis y qué se puede ignorar de forma segura. A veces, se encuentra un CVE en un paquete que realmente no se utiliza en la versión de producción de la aplicación. Por ejemplo, un paquete puede instalarse como resultado de una dependencia indirecta de algún marco de prueba. Para solucionar esto, los escáneres deben evaluar el alcance de los archivos de la aplicación e identificar las dependencias indirectas en uso.
Los complementos de OWASP (The Open Worldwide Application Security Project) tienen algunos buenos ejemplos de herramientas que pueden ayudar con los problemas de alcance. Comprobación de dependencias de OWASP, por ejemplo, puede analizar las dependencias de una aplicación e identificar CVE en el contexto del gráfico de dependencia de la aplicación. Al hacerlo, puede identificar qué CVE están en uso en la aplicación de producción y cuáles no.
Cualquiera que sea el número, aún necesita abordar sus CVE
En ausencia de alguna otra herramienta que pueda indicarle dónde su aplicación es vulnerable a posibles ataques, puertas traseras y otros problemas similares, un escaneo CVE sigue siendo una opción bastante básica para abordar problemas potenciales. El problema es que hasta que verifique si un CVE que se le presenta en el análisis es un problema real, representa una amenaza que los reguladores, terceros y usuarios pueden utilizar en su contra.
En nombre de la seguridad y la transparencia, debe analizar cada problema potencial y demostrar que no es un problema, no es relevante para su aplicación o es un problema potencial y está trabajando para solucionarlo. El hecho de que muchos de estos CVE lleguen a su aplicación desde paquetes externos, generalmente de código abierto, significa que incluso si lo identifica como un exploit potencial, probablemente aún necesitará la ayuda de los mantenedores del paquete para parchearlo.
Con todo este trabajo asociado con cada CVE, no es de extrañar que prefieras obtener un número lo más pequeño posible en tu próximo escaneo de CVE. Usar algunas de las sugerencias descritas en este artículo podría ayudar a que la monumental tarea de abordar sus vulnerabilidades sea un poco más manejable.
Si tiene otras herramientas gratuitas o de código abierto para solucionar el problema, nos encantaría conocerlas. Cuéntanoslo en los comentarios y comparte con la comunidad cómo manejas tu montaña de vulnerabilidades.

Este contenido es presentado por Scribe Security, un proveedor líder de soluciones de seguridad de la cadena de suministro de software de extremo a extremo, que ofrece seguridad de última generación para artefactos de código y procesos de desarrollo y entrega de código en todas las cadenas de suministro de software. Más información.
Artículos relacionados con


