業界はまだ SBOM の概念を完全には理解していませんが、すでに ML-BOM (機械学習部品表) という新しい用語を耳にし始めています。パニックが始まる前に、なぜこのような BOM を作成する必要があるのか、ML-BOM を生成する際の課題、およびそのような ML-BOM がどのようなものかを理解しましょう。
このブログを読んでいると、この記事が AI によって生成されたのかどうか自問するかもしれません。その理由は、AIが私たちの周りにあふれており、人工物と区別することが難しいためです。しかし、AI の急速な進歩は、個人的、商業的、社会的なリスクももたらしており、これらのリスクを制限するための法律が制定され始めています。 EUAI法。これらのリスクを深く掘り下げることはこの記事の範囲外ですが、いくつか挙げると、AI を活用したシステム、IP、ライセンス、およびサイバーには、安全ではなく、差別的で、プライバシーを侵害する行為のリスクがあります。 -セキュリティリスク。
これらのリスクに対処するための最初のステップは、各システム内でどの AI テクノロジーが使用されているかを知ることです。このような知識により、利害関係者はリスクを管理し(たとえば、データセットとモデルのライセンスを知ることで法的リスクを管理する)、これらのテクノロジーに関する新しい発見に対応できるようになります(たとえば、モデルが差別的であることが判明した場合、利害関係者はすべてをマッピングできます)リスクを軽減するためにこのモデルを使用するシステム)。
進化する規制を一瞥し、調査する 令13960 「連邦政府における信頼できる人工知能の使用の促進」に関する論文では、説明責任、透明性、責任、トレーサビリティ、規制監視などの原則が明らかにされており、これらすべての原則には、各システムでどの AI テクノロジーが使用されているかを理解する必要があります。
ML-BOM は、製品内の AI テクノロジーの文書です。 SBOM のよく知られた OWASP 形式である CycloneDX バージョン 1.5 以降は、これをサポートしており、現在 ML-BOM の標準となっています。
ML-BOM の生成は困難です。モデルとデータセットを表す方法はたくさんあります。 AI モデルとデータセットはその場で利用でき、どのモデルを使用するかの決定は、標準的なコンポーネント分析テクノロジーが検出するための痕跡を残すことなく、プログラムによってその場で行うことができます。これらの課題に加えて、ソフトウェア パッケージ マネージャーが成熟しているのとは対照的に、AI はまだ新興テクノロジーです。そのため、業界は ML-BOM のニーズをまだ完全に理解していません。
出発点として、私たちは事実上の標準である HuggingFace を使用するプロジェクトの ML-BOM の生成に焦点を当てることにしました。 HuggingFace は AI モデルとデータセットの「パッケージ マネージャー」であり、一般的な Python ライブラリが付属しています。以下は、このような製品から自動的に生成された SBOM のスナップショットのいくつかです。
多くのコンポーネントで構成されている製品を想像してください。そのうちのいくつかは機械学習モデルです。以下の CycloneDX コンポーネントは、そのようなモデルを説明しています。
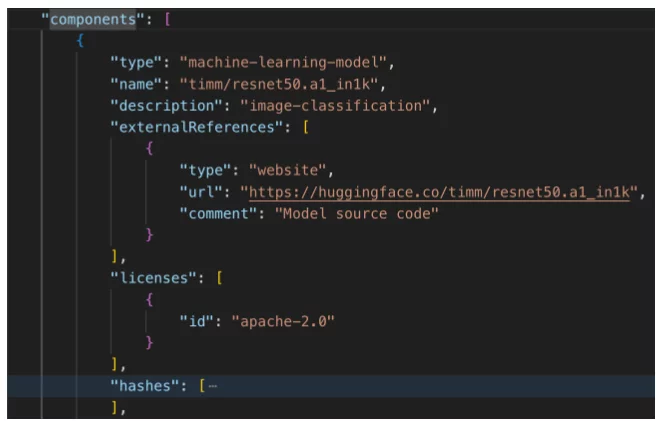
機械学習モデルコンポーネント (パート 1) – 標準 CycloneDX コンポーネントデータ
このコンポーネントはモデルを識別し、このモデルに関する情報をさらに調べるためのリンクを提供します。さらに、コンプライアンスの目的で使用できるライセンス情報も含まれています。
CycloneDX V1.5 では、機械学習モデルのプロパティを文書化する標準的な方法として、「modelCard」という AI 固有のフィールドも定義されています。以下は、作成したmodelCardの例です。
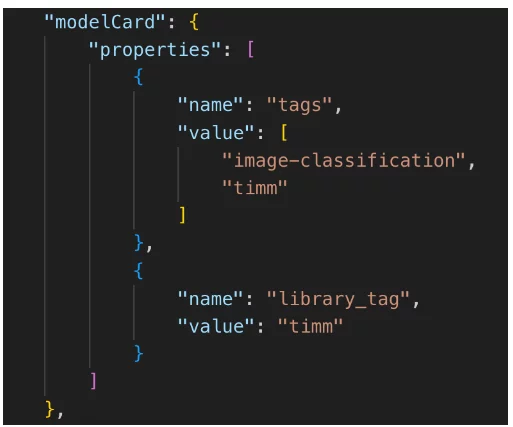
機械学習モデル コンポーネント (パート 2) – データ カード
このような modelCard の使用例としては、画像分類モデルを使用するすべての製品を検索したり、特定のモデル タイプの使用を禁止するポリシーを実行したりすることが考えられます。
CycloneDX を使用すると、コンポーネント ツリー - サブコンポーネント階層のドキュメント化が可能になります。 HuggingFace は AI パッケージ マネージャーとして、AI モデルとデータセットを git リポジトリとして表すため、AI モデル/データセットのファイルを機械学習モデル コンポーネントのサブコンポーネントとして文書化することにしました。これは次のようになります。
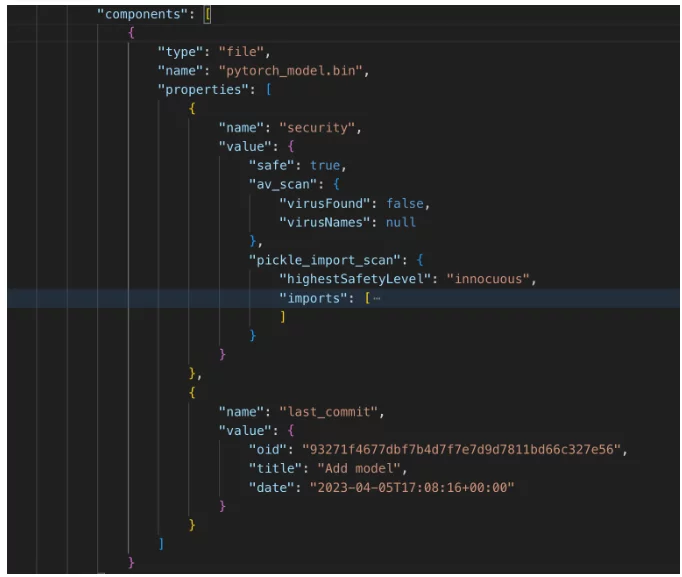
機械学習モデル コンポーネント (パート 3) – サブコンポーネント
プロパティには、標準のファイル情報に加えて、セキュリティ情報などの追加情報が含まれます。この場合、次の 2 つのセキュリティ対策が見られます。
- ウイルス スキャン – ウイルスの影響を受けやすいデータセット (画像、PDF、実行可能ファイルなど) を使用する場合に重要です。
- Pickle スキャン – リスクがより発生しやすい「pickle」タイプのデータセット ファイルに関するセキュリティ リスク対策 (この形式のリスクを理解するには、 ハグフェイスのウェブサイト).
このデータを使用して、ウイルスおよびピクルス スキャンが正常に通過したことを検証するポリシーを適用できます。
ML-BOM は新しい概念です。ここで示すものは最初のステップです。しかし、たとえそうだとしても、AI の導入、規制、リスクの高まりを考慮すると、AI がもたらす価値は理解できます。
最後のメモとして、私は私の水晶球 (別名 ChatGPT) に ML-BOM の将来について説明するように依頼しました。その答えは次のとおりです。
「そう遠くない将来、ML-BOM は、複雑な CI/CD パイプラインをタップダンスしながら、自動化のセンスで機械学習モデルのシンフォニーをオーケストレーションする、サイバーに精通した自動操縦のマエストロに進化するかもしれません。 」
まあ、おそらく ML-BOM 以外にも必要なものがあるでしょう...
このコンテンツは、エンドツーエンドのソフトウェア サプライ チェーン セキュリティ ソリューションの大手プロバイダーである Scribe Security によって提供されており、ソフトウェア サプライ チェーン全体のコード成果物とコード開発および配信プロセスに最先端のセキュリティを提供しています。 詳しくはこちら。
関連記事


