CVE (Vulnerabilità ed esposizioni comuni) sono essenziali per proteggere le applicazioni software. Tuttavia, con la crescente complessità degli stack software, identificare e gestire tutti i CVE può essere difficile. Uno dei maggiori problemi con le scansioni CVE oggi è la prevalenza di falsi positivi, in cui viene identificata una vulnerabilità in un pacchetto che non è in uso nell'applicazione di produzione.
È importante ricordare che anche una volta ottenuto un elenco completo di tutti i pacchetti software e un elenco completo di tutti i CVE presenti in tali pacchetti è abbastanza certo che non tutti sono rilevanti per la tua applicazione. Il CVE potrebbe trovarsi in una funzione che non è in uso nel tuo codice o in una parte della libreria che non chiami nemmeno. Potrebbe trovarsi in una dipendenza temporanea che viene chiamata solo a causa di un elenco di dipendenze senza patch e non è affatto utilizzata nel codice. Anche una volta che sai che un CVE si trova in una parte di una libreria che usi, non è garantito che il CVE sia effettivamente sfruttabile nella tua applicazione. Alcuni exploit richiedono condizioni estreme per essere utilizzabili dagli hacker, inclusa la combinazione di 3 o più CVE in sequenza, lo stack corretto e la giusta infrastruttura. Dato che devi ancora dare un'occhiata più da vicino a ogni CVE che ottieni dalla tua scansione, puoi vedere quanto sia importante vagliare il numero di CVE che ottieni in modo da non soffrire di affaticamento da allerta o burnout CVE prima di poter tornare indietro per creare effettivamente le prossime funzionalità della tua applicazione.
In questo articolo offrirò alcune possibili soluzioni per mitigare i falsi positivi nelle scansioni CVE, con l'obiettivo di ridurre il numero complessivo di CVE da gestire. Inizierò discutendo le sfide legate all'identificazione dei pacchetti, quindi passerò all'introduzione di un database che associa i file dei pacchetti ai nomi dei pacchetti. Discuterò anche i problemi relativi all'ambito e al percorso del codice che possono causare falsi positivi.
Cominciamo innanzitutto esaminando come vengono identificati i CVE.
Il pacchetto misterioso e il CVE mancante
La Mitre Corporation è un'organizzazione americana senza fini di lucro che si occupa della Programma CVE®. I programmi la missione è identificare, definire e catalogare le vulnerabilità della sicurezza informatica divulgate pubblicamente. Il modo in cui funziona è che una volta trovata una vulnerabilità si compila un modulo e, se la scoperta può essere confermata, viene assegnato un nuovo identificatore CVE alla vulnerabilità e viene aggiunto al database CVE pubblico.
Considerando il modo in cui sono elencati i CVE, una delle sfide principali con le scansioni CVE è identificare correttamente i pacchetti e le librerie. Quando qualcuno identifica una vulnerabilità in un pacchetto o in una libreria, la elenca con il nome del pacchetto e la versione con cui ha familiarità. Naturalmente non tutti gli strumenti utilizzano le stesse convenzioni di denominazione e i nomi dei pacchetti non hanno uno standard globale esistente. Il "problema della denominazione", come è diventato noto, è abbastanza grave che diversi forum e gruppi di riflessione stanno cercando da molto tempo di trovare una soluzione comune. Ad esempio, ecco La soluzione proposta da OWASP per il problema in quanto si riferisce alla creazione di SBOM. Spesso, gli strumenti di scansione fanno affidamento sulle fonti a cui vengono alimentati, come artefatti costruiti o compilati, per i nomi dei pacchetti che forniscono nel risultato della scansione e queste fonti non sono sempre affidabili. Ad esempio, involucri e adattamenti possono rendere difficile l'identificazione della confezione vera e propria. Inoltre, alcuni file di pacchetto potrebbero non lasciare traccia del pacchetto di installazione, come i comandi COPY di Docker.
Per affrontare questi problemi, noi, a Scriba Sicurezza, suggerisci di creare un database per la tua applicazione che associ i file dei pacchetti ai nomi dei pacchetti. Anche se il nome del pacchetto è diverso, se si tratta dello stesso pacchetto, i file e gli hash dei file sarebbero identici. In questo modo, puoi evitare problemi che coinvolgono wrapper e adattamenti e identificare il pacchetto effettivo che deve essere risolto. Questo approccio può far risparmiare tempo e fatica nel processo di correzione CVE. Dal momento che Piattaforma Scriba sta già identificando i file associati a ciascun pacchetto incluso nell'immagine finale, la creazione di tale database è il passo logico successivo. Intendiamo che la nostra scansione CVE non debba basarsi sul nome e sulla versione elencati dal CVE, ma sui file effettivi inclusi nel pacchetto.
Sei la mia mamma?
Quando si ha a che fare con una build finale che è un'immagine Docker, oggigiorno è pratica comune non iniziare da zero. Avere un punto di partenza solido, come un'immagine di base consolidata, consente agli sviluppatori di concentrarsi sulla parte della build che costituisce la loro applicazione anziché iniziare a pianificare l'ambiente su cui deve essere eseguita. Una delle sfide nell'utilizzo delle immagini Docker è comprenderne la provenienza e le dipendenze, in particolare quando si tratta dell'immagine principale (a parte l'immagine di base) su cui è costruita l'immagine finale.
L'immagine genitore è un concetto a cui abbiamo pensato per spiegare il "parente vivente" più vicino di un'immagine Docker. Le immagini sono costruite in livelli distinti, quindi, diciamo che utilizzo un'immagine di base nota, come Alpine, Debian o Ubuntu, e creo il mio livello di applicazione proprio sopra di essa. In questo caso, il mio "genitore" più vicino sarebbe quell'immagine di base. Ma cosa succede se l’azienda per cui lavoro ha un punto di partenza diverso, che include un’immagine di base e alcuni livelli aggiuntivi oltre a quelli degli strumenti di sicurezza obbligatori per tutte le immagini aziendali? In questo caso, la mia immagine principale sarebbe questo modello aziendale e sarei anche in grado di identificare l'immagine di base su cui è stato creato questo modello.
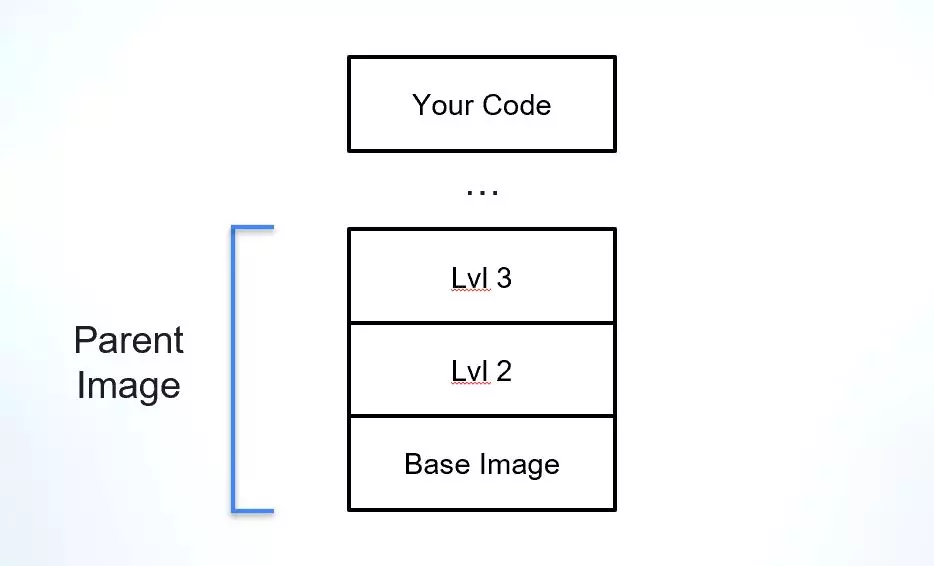
L'immagine principale è una parte cruciale della catena di fornitura del software, poiché fornisce le basi per l'applicazione e le sue dipendenze. Nativamente, le immagini Docker non includono molte informazioni sull'origine delle immagini principali o di base, rendendo difficile verificarne l'integrità, comprenderne le vulnerabilità e verificarne la licenza.
Per risolvere questo problema, Scribe ha sviluppato uno strumento e un servizio open source chiamato ParentImage per rilevare il genitore scansionato più vicino di un'immagine Docker. Questo strumento può essere utilizzato per identificare l'immagine principale di un'immagine Docker, che è un fattore chiave di riduzione del rischio:
Innanzitutto, identificando l'immagine di base, è possibile verificarne l'integrità e assicurarsi che non sia stata manomessa o compromessa. Questo è importante per mantenere la sicurezza e la stabilità dell'applicazione.
In secondo luogo, comprendendo quali vulnerabilità provengono dall'immagine principale e quali dal livello dell'applicazione stessa, è possibile stabilire le priorità e gestire le vulnerabilità in modo più efficace. Ciò significa che i CVE collegati alla tua immagine di base o all'immagine principale sono meno urgenti (e non sempre è tua responsabilità correggerli) rispetto ai CVE nel livello dell'applicazione.
Inoltre, identificando l'immagine principale, è possibile verificarne la licenza e garantire la conformità ai requisiti legali e alle politiche interne.
Lo strumento open source ParentImage include un database aggiornabile di scansioni di immagini Docker. Puoi eseguirne il fork e utilizzarlo completamente internamente, ma speriamo che le persone scansionino le loro immagini Docker e ci inviino le informazioni da includere nel database. Maggiore è il numero di scansioni di immagini incluse nel database, maggiore è il numero di "Genitori" che lo strumento sarà in grado di identificare. Attualmente, il database incluso contiene un elenco completo di tutte le immagini di base stabilite come prova di concetto. Essendo uno strumento open source, provarlo non costa nulla, quindi se utilizzi immagini Docker ti incoraggio a considerare questo strumento come un possibile rimedio a uno dei motivi per CVE non correlati.
Devo eseguire la scansione o devo saltare?
Un'altra sfida con le scansioni CVE riguarda i problemi di definizione dell'ambito. L'ambito si riferisce alla posizione dei file e dei pacchetti scansionati: cosa dovrebbe essere incluso nella scansione e cosa può essere tranquillamente ignorato. A volte, un CVE viene trovato in un pacchetto che non è effettivamente in uso nella versione di produzione dell'applicazione. Ad esempio, un pacchetto potrebbe essere installato come risultato di una dipendenza indiretta da qualche framework di test. Per risolvere questo problema, gli scanner devono valutare l'ambito dei file dell'applicazione e identificare le dipendenze indirette in uso.
I plugin OWASP (The Open Worldwide Application Security Project) hanno alcuni buoni esempi di strumenti che possono aiutare con l'ambito dei problemi. Controllo delle dipendenze OWASP, ad esempio, può analizzare le dipendenze di un'applicazione e identificare CVE nel contesto del grafico delle dipendenze dell'applicazione. In questo modo è possibile identificare quali CVE sono in uso nell'applicazione di produzione e quali no.
Qualunque sia il numero, devi comunque indirizzare i tuoi CVE
In assenza di qualche altro strumento in grado di dirti dove la tua applicazione è vulnerabile a possibili hack, backdoor e altri problemi simili, una scansione CVE è ancora un'opzione piuttosto semplice per affrontare potenziali problemi. Il problema è che finché non verifichi se un CVE presentato durante la scansione è un problema reale, rappresenta una minaccia che può essere utilizzata contro di te dalle autorità di regolamentazione, da terze parti e dagli utenti.
In nome della sicurezza e della trasparenza, devi esaminare ogni potenziale problema e dimostrare che non è un problema, non è rilevante per la tua applicazione, oppure è un potenziale problema e stai lavorando per risolverlo. Il fatto che molti di questi CVE arrivino nella tua applicazione da pacchetti esterni, solitamente open source, significa che anche se lo identifichi come un potenziale exploit probabilmente avrai comunque bisogno dell'aiuto dei manutentori del pacchetto per correggerlo.
Con tutto questo lavoro associato a ciascun CVE, non c'è da meravigliarsi che preferiresti ottenere il numero più piccolo possibile nella prossima scansione CVE. L’utilizzo di alcuni dei suggerimenti delineati in questo articolo potrebbe aiutare a rendere un po’ più gestibile l’enorme compito di affrontare le proprie vulnerabilità.
Se disponi di altri strumenti open source o gratuiti per affrontare il problema, ci piacerebbe saperlo. Raccontacelo nei commenti e condividi con la community come gestisci la tua montagna di vulnerabilità.

Questo contenuto è offerto da Scribe Security, un fornitore leader di soluzioni di sicurezza end-to-end per la catena di fornitura di software, che offre sicurezza all'avanguardia per artefatti di codice e processi di sviluppo e distribuzione del codice attraverso le catene di fornitura di software. Per saperne di più.
Post Correlati


