CVE (Vulnérabilités et expositions communes) les analyses sont essentielles à la sécurisation de vos applications logicielles. Cependant, avec la complexité croissante des piles logicielles, identifier et traiter tous les CVE peut s'avérer difficile. L’un des plus gros problèmes liés aux analyses CVE aujourd’hui est la prévalence des faux positifs, lorsqu’une vulnérabilité est identifiée dans un package qui n’est pas utilisé dans l’application de production.
Il est important de se rappeler que même une fois que vous avez obtenu une liste complète de tous vos packages logiciels et une liste complète de tous les CVE trouvés dans ces packages, il est presque certain que tous ne sont pas pertinents pour votre application. Le CVE peut se trouver dans une fonction qui n'est pas utilisée dans votre code ou dans une partie de la bibliothèque que vous n'appelez même pas. Il peut s'agir d'une dépendance transitoire qui n'est appelée qu'en raison d'une liste de dépendances non corrigée et qui n'est pas du tout utilisée dans votre code. Même une fois que vous savez qu'un CVE se trouve dans une partie d'une bibliothèque que vous utilisez, cela ne garantit pas que le CVE soit réellement exploitable dans votre application. Certains exploits nécessitent des conditions extrêmes pour être utilisables par les pirates informatiques, notamment la combinaison de 3 CVE ou plus en séquence, la bonne pile et la bonne infrastructure. Puisque vous devez toujours examiner de plus près chaque CVE que vous obtenez à partir de votre analyse, vous pouvez voir à quel point il est important de réduire le nombre de CVE que vous obtenez afin de ne pas subir de fatigue d'alerte ou d'épuisement des CVE avant de pouvoir revenir. pour créer réellement les prochaines fonctionnalités de votre application.
Dans cet article, je proposerai quelques solutions possibles pour atténuer les faux positifs dans les analyses CVE, dans le but de réduire le nombre global de CVE que vous devez traiter. Je commencerai par discuter des défis liés à l'identification des packages, puis je passerai à l'introduction d'une base de données qui mappe les fichiers de package aux noms de package. Je discuterai également des problèmes de portée et de chemin de code qui peuvent provoquer des faux positifs.
Commençons par examiner comment les CVE sont identifiés en premier lieu.
Le package mystère et le CVE manquant
La Mitre Corporation est une organisation américaine à but non lucratif qui est en charge du Programme CVE®. Les programmes La mission est d’identifier, de définir et de cataloguer les vulnérabilités de cybersécurité divulguées publiquement. La façon dont cela fonctionne est qu'une fois que vous avez trouvé une vulnérabilité, vous remplissez un formulaire et, si la découverte peut être corroborée, un nouvel identifiant CVE est attribué à la vulnérabilité et il est ajouté à la base de données publique CVE.
Compte tenu de la manière dont les CVE sont répertoriés, l'un des principaux défis des analyses CVE est d'identifier correctement les packages et les bibliothèques. Lorsqu'une personne identifie une vulnérabilité dans un package ou une bibliothèque, elle la répertorie avec le nom du package et la version qu'elle connaît. Bien entendu, tous les outils n’utilisent pas les mêmes conventions de dénomination et les noms de packages n’ont pas de norme mondiale existante. Le « problème de dénomination », comme on l'appelle désormais, est suffisamment grave pour que de nombreux forums et groupes de réflexion tentent depuis longtemps de trouver une solution commune. A titre d'exemple, voici La solution proposée par l'OWASP pour le problème lié à la création de SBOM. Souvent, les outils d'analyse s'appuient sur les sources qu'ils alimentent, telles que les artefacts construits ou compilés, pour les noms de packages qu'ils fournissent dans le résultat de l'analyse et ces sources ne sont pas toujours fiables. Par exemple, les wrappers et les adaptations peuvent rendre difficile l’identification du package réel. De plus, certains fichiers de package peuvent ne laisser aucune trace de leur package d'installation, comme les commandes Docker COPY.
Pour résoudre ces problèmes, nous, à Scribe Sécurité, suggérez de créer une base de données pour votre application qui mappe les fichiers de package aux noms de package. Même si le nom du package est différent, s’il s’agit du même package, les fichiers et les hachages de fichiers seraient identiques. Ce faisant, vous pouvez ignorer les problèmes impliquant des wrappers et des adaptations et identifier le package réel qui doit être résolu. Cette approche peut permettre d'économiser du temps et des efforts dans le processus de remédiation CVE. Depuis le Plateforme de scribe identifie déjà les fichiers associés à chaque package inclus dans votre image finale, la création d'une telle base de données est la prochaine étape logique. Nous avons l'intention que notre analyse CVE ne doive pas s'appuyer sur le nom et la version répertoriés par le CVE, mais sur les fichiers réels inclus dans le package.
Es tu ma mère?
Lorsqu'il s'agit d'une version finale qui est une image Docker, il est courant de nos jours de ne pas repartir de zéro. Disposer d'un point de départ solide, tel qu'une image de base établie, permet aux développeurs de se concentrer sur la partie de la version qui constitue leur application plutôt que de commencer à planifier l'environnement sur lequel elle doit s'exécuter. L'un des défis liés à l'utilisation des images Docker est de comprendre leur provenance et leurs dépendances, en particulier lorsqu'il s'agit de l'image parent (en dehors de l'image de base) sur laquelle l'image finale est construite.
L'image parent est un concept auquel nous avons pensé pour expliquer le « parent vivant » le plus proche d'une image Docker. Les images sont construites en couches distinctes, donc disons que j'utilise une image de base connue, telle que Alpine, Debian ou Ubuntu, et que je construis ma couche d'application juste au-dessus. Dans ce cas, mon « parent » le plus proche serait cette image de base. Mais que se passe-t-il si l’entreprise pour laquelle je travaille a un point de départ différent, qui inclut une image de base et quelques couches supplémentaires en plus de celle des outils de sécurité obligatoires pour toutes les images de l’entreprise ? Dans ce cas, mon image parent serait ce modèle d'entreprise et je serais également en mesure d'identifier l'image de base sur laquelle ce modèle a été construit.
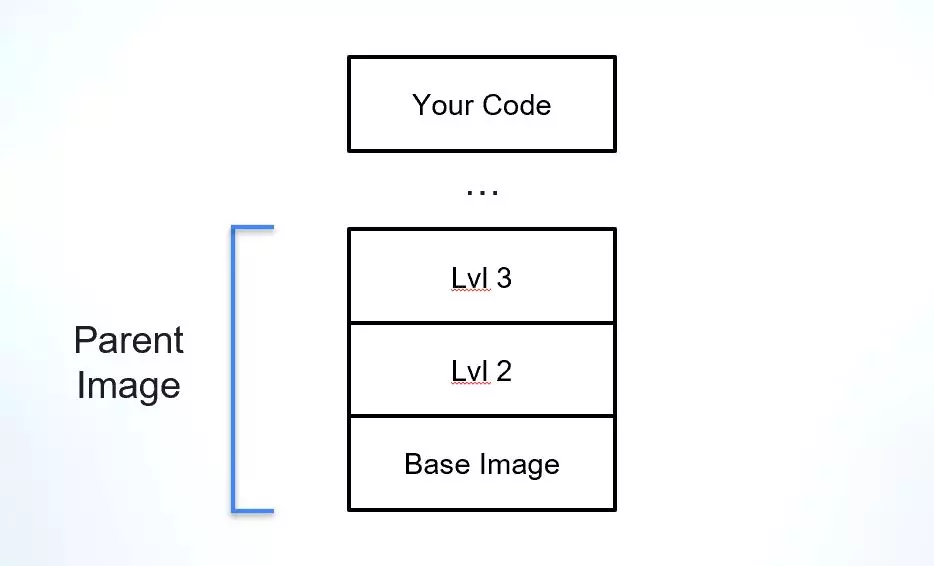
L'image parent est un élément crucial de votre chaîne d'approvisionnement logicielle, car elle constitue la base de l'application et de ses dépendances. Nativement, les images Docker n'incluent pas beaucoup d'informations sur l'origine de leurs images parentes ou de base, ce qui rend difficile la vérification de leur intégrité, la compréhension de leurs vulnérabilités et la vérification de leur licence.
Pour résoudre ce problème, Scribe a développé un outil et un service open source appelés ImageParent pour détecter le parent numérisé le plus proche d'une image Docker. Cet outil peut être utilisé pour identifier l'image parent d'une image Docker, ce qui constitue un facteur clé de réduction des risques :
Premièrement, en identifiant l’image de base, on peut vérifier son intégrité et s’assurer qu’elle n’a pas été falsifiée ou compromise. Ceci est important pour maintenir la sécurité et la stabilité de l’application.
Deuxièmement, en comprenant quelles vulnérabilités proviennent de l’image parent et lesquelles proviennent de la couche application elle-même, on peut hiérarchiser et gérer les vulnérabilités plus efficacement. Cela signifie que les CVE liés à votre image de base ou à votre image parent sont moins urgents (et il ne vous incombe pas toujours d'y remédier) par rapport aux CVE de la couche d'application.
De plus, en identifiant l'image parent, on peut vérifier sa licence et garantir la conformité aux exigences légales et de politique interne.
L'outil open source ParentImage comprend une base de données actualisable d'analyses d'images Docker. Vous pouvez le créer et l'utiliser entièrement en interne, mais nous espérons que les gens scanneront leurs images Docker et nous enverront ces informations pour les inclure dans la base de données. Plus la base de données comprend d'images analysées, plus l'outil sera capable d'identifier de « parents ». Actuellement, la base de données incluse contient une liste complète de toutes les images de base établies comme preuve de concept. En tant qu'outil open source, l'essayer ne coûte rien, donc si vous utilisez des images Docker, je vous encourage à considérer cet outil comme un remède possible à une raison de CVE sans rapport.
Dois-je numériser ou dois-je ignorer ?
Un autre défi des analyses CVE concerne les problèmes de portée. La portée fait référence à l'emplacement des fichiers et des packages analysés : ce qui doit être inclus dans l'analyse et ce qui peut être ignoré en toute sécurité. Parfois, un CVE se trouve dans un package qui n'est pas réellement utilisé dans la version de production de l'application. Par exemple, un package peut être installé suite à une dépendance indirecte à un framework de test. Pour résoudre ce problème, les scanners doivent évaluer la portée des fichiers d'application et identifier les dépendances indirectes utilisées.
Les plugins OWASP (The Open Worldwide Application Security Project) contiennent de bons exemples d'outils qui peuvent aider à résoudre les problèmes de portée. Vérification des dépendances OWASP, par exemple, peut analyser les dépendances d'une application et identifier les CVE dans le contexte du graphe de dépendances de l'application. Ce faisant, il peut identifier quels CVE sont utilisés dans l'application de production et lesquels ne le sont pas.
Quel que soit le nombre, vous devez toujours répondre à vos CVE
En l'absence d'un autre outil capable de vous indiquer où votre application est vulnérable à d'éventuels piratages, portes dérobées et autres problèmes similaires, une analyse CVE reste une option assez basique pour résoudre les problèmes potentiels. Le problème est que jusqu'à ce que vous vérifiiez si un CVE qui vous est présenté lors de l'analyse est un problème réel, il représente une menace qui peut être utilisée contre vous par les régulateurs, les tiers et les utilisateurs.
Au nom de la sécurité et de la transparence, vous devez examiner chaque problème potentiel et prouver qu'il ne s'agit pas d'un problème, qu'il n'est pas pertinent pour votre application ou qu'il s'agit d'un problème potentiel et que vous travaillez à le corriger. Le fait qu'un grand nombre de ces CVE proviennent de packages externes, généralement open source, dans votre application signifie que même si vous l'identifiez comme un exploit potentiel, vous aurez probablement toujours besoin de l'aide des responsables du package pour le corriger.
Avec tout ce travail associé à chaque CVE, il n'est pas étonnant que vous préfériez en obtenir le plus petit nombre possible lors de votre prochaine analyse CVE. L’utilisation de certaines des suggestions décrites dans cet article pourrait contribuer à rendre la tâche monumentale consistant à remédier à vos vulnérabilités un peu plus gérable.
Si vous disposez d'autres outils open source ou gratuits pour résoudre le problème, nous serions ravis d'en entendre parler. Parlez-nous-en dans les commentaires et partagez avec la communauté comment vous gérez votre montagne de vulnérabilités.

Ce contenu vous est proposé par Scribe Security, l'un des principaux fournisseurs de solutions de sécurité de bout en bout pour la chaîne d'approvisionnement logicielle, offrant une sécurité de pointe aux artefacts de code ainsi qu'aux processus de développement et de livraison de code tout au long des chaînes d'approvisionnement logicielles. En savoir plus.
articles similaires


