Securing Your Software Supply Chain begins with the Discovery and Governance of Your ‘Software Factory’
In today’s software development environment, teams handle decentralized assets such as code repositories, build pipelines, and container images. While this distributed model offers flexibility and speeds up production, it also fragments assets and complicates governance and security oversight, especially as cloud-native applications become more widespread.
As a result, security teams often lose valuable time tracking down code owners for orphaned production workloads when security issues arise or when unsanctioned software artifacts make their way to production. The software supply chain has become a critical attack surface, and it’s essential to gather security signals early—from development through to build stages—to avoid blind spots and ensure that all assets across the Software Development Lifecycle (SDLC) are monitored.
DevSecOps teams typically lack automated tools to continuously map this shifting development landscape, where new code paths and tools are frequently introduced. Information often remains siloed across various platforms, making it difficult to access for security purposes. Dev platforms and tools often vary across the development, integration, and deployment as software is promoted through the stages.
While Application Security Posture Management (ASPM) and observability vendors aggregate security scans, they often fail to provide a complete view that connects code paths to production.
The presence of outdated assets compounds the issue. Identifying which repositories are still active in production can be overwhelming, particularly for large organizations. Mergers and acquisitions further complicate this by adding diverse platforms and development standards.
DevSecOps teams often resort to manual processes—like filling out manifests or labeling containers—which are tedious, prone to error, and often sidelined in favor of more urgent priorities.
Think of it like defending a constantly shifting battleground, where security teams need an accurate map to protect their assets. These assets are always moving in development, and new targets must be identified and secured. To address this, an ongoing discovery mechanism is required to map changes as they happen.
Best practices and frameworks support this approach. For instance, the Cybersecurity and Infrastructure Security Agency (CISA) mandates that organizations verify the provenance of software components and maintain a comprehensive inventory as part of their self-attestation process. Similarly, the NIST Secure Software Development Framework (SSDF) and the OWASP DevSecOps Maturity Model (DSOMM) emphasize the importance of continuous discovery and visibility.
In the rest of this post, we will outline a blueprint for addressing these challenges and explore how Scribe Security helps organizations implement these capabilities effectively.
Scribe’s Blueprint for Effective Discovery
Discovery generates a map modeled in a graph, providing a view of assets, relationships and your factory’s security posture. This allows for:
- Complete visibility and ownership control.
- Enhanced querying capabilities.
- Monitoring of KPIs and security maturity metrics.
- Quicker identification and prioritization of risk factors.
- Initial Scan
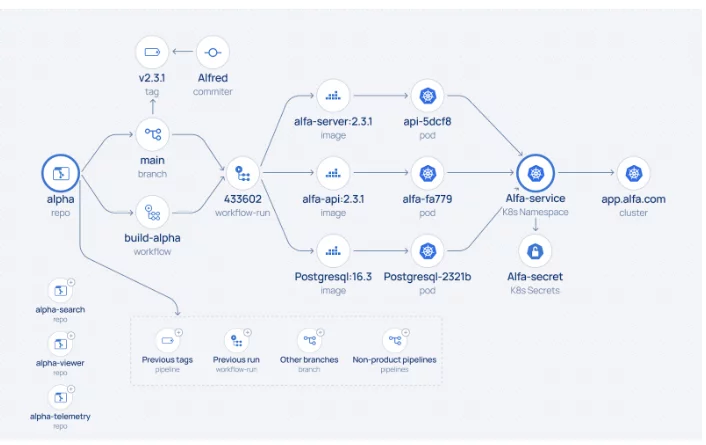
The initial scan aims to create a high-level map of assets, focusing on identifying those that require further analysis. A full deep scan can be time-consuming, and many assets, such as those not linked to production or obsolete, may be irrelevant. This initial scan typically gathers basic details like repository names, IDs, and activity statistics but doesn’t include a complete list of commits or contributors.
One method is scanning from “right to left.” By accessing production environments (e.g., via the K8s cluster API), the scanner can identify running container images—critical assets that reflect business value. From there, the scan traces back to the container registry and relevant repositories. The scan typically halts here, as there’s usually no direct connection between the registry and the preceding SDLC pipeline.
Complementary scans can be run from “left to right,” identifying code repositories, build pipelines, and registries across different SDLC stages (e.g., Development, Integration, Testing).
The outcome is a prioritized list of assets across platforms, ready for deep scanning to trace the lineage from code to production and assess the SDLC’s security posture. Prioritization is based on factors like relevance to production, activity level, and recency. Sometimes, institutional knowledge of asset significance helps guide this process.
The initial scan can be scheduled periodically or triggered by events like code pushes. Subsequent scans can apply automatic selection criteria, such as using globs for deep scanning newly discovered assets.
- Deep Scan
Once relevant assets are prioritized, the deep scan collects detailed attributes that establish relationships among assets, such as branch IDs, commit and committer IDs, and pipeline run IDs. The duration of this scan can vary depending on the scope of the assets and API rate limits.
By the end of this stage, an asset relationship graph begins to take shape, with clusters of connected assets around code repositories (containing build information) and runtime environments (with registry assets). However, a complete lineage is still incomplete, as registries typically don’t store information about the pipelines that pushed the build artifacts.
- Connecting the Clusters
Once the inventory is established, the lineage can be completed by instrumenting a CLI tool in the pipeline to capture build provenance details or by processing CI logs. Instrumentation is the most reliable method, recording key attributes like code repository IDs, pipeline and run IDs, and image IDs. It links previously isolated clusters effectively and creates a complete end-to-end lineage from code to production.
A complementary approach is CI log processing, which retrieves relevant attributes but requires more resources and depends on existing logging. While this method offers quicker implementation, combining both approaches yields the best results—instrumenting critical pipelines and using log analysis for newly discovered ones, which can then be evaluated for further instrumentation.
This clustering approach also considers aggregating separate lineages into a unified structure for complex products, such as web applications composed of multiple components, such as microservices.
- Software Bill of Materials (SBOM)
Up to this point, the focus has been on connecting development assets across platforms establishing a clear lineage from code to production for relevant assets. Now, attention shifts to the composition of the software artifacts themselves. In this step, an SBOM is generated from those artifacts and their associated code repositories, adding them to the existing inventory.
By synthesizing a code repository and artifact SBOMs into a single SBOM, with logic to correlate dependencies and exclude irrelevant ones—such as development and testing libraries—the result is a more accurate and comprehensive SBOM than either source could provide alone.
- Security posture and DevSecOPs KPIs
Continuously mapping the asset inventory and their relationships offers the best opportunity to assess the security posture of these assets. Key factors include access permissions for human and non-human identities, code signature verification, risky or vulnerable dependencies, and security settings across various platforms and accounts.
This data can be aggregated into different dimensions to measure KPIs for product releases, deployment times to production, and DevSecOps maturity. Specifically, it allows teams to evaluate the adoption of security controls, such as code signing and adherence to security settings, helping to track progress and ensure robust security practices.
- Visualization and Querying of the SDLC and Software Supply Chain Graph
One key benefit of the discovery process is the ability to visualize the SDLC and software supply chain as a dynamic graph or “battle map.” This visualization offers a comprehensive view of the entire development lifecycle, making tracking assets and their relationships easier.
The real power comes from the ability to query the graph, enabling teams to ask critical questions, such as:
- “Which component failed a security check during its build or deployment?”
- “Which workloads in production are orphaned?”
- “Who committed the change that introduced a vulnerability?”
- “Who owns the asset that needs to be patched?”
Querying the lineage helps teams identify the root cause of issues, which is a clear advantage over manual documentation. Manually maintained ownership mappings quickly become outdated, often leading DevSecOps teams on inefficient searches for the right stakeholders. In contrast, a queryable graph ensures that ownership and accountability are always up-to-date, reducing time wasted tracking down responsibility for code or infrastructure.
- Deployment Options for Discovery Tools
Organizations have varied needs for deploying discovery tools, and offering flexible deployment options is essential to meet different security requirements. Some teams prefer remote access via a SaaS platform, simplifying management and scaling. On the other hand, teams with stricter security protocols might choose local scanner deployment to maintain tighter control over sensitive credentials, such as development platform API tokens. The choice between SaaS and local deployment depends on factors like the organization’s security posture, compliance needs, and control over data.
Conclusion
Securing your software supply chain is an ongoing battle; no organization should enter it without a clear map. By implementing a robust discovery process, you gain comprehensive visibility across your SDLC and supply chain, ensuring that every asset is accounted for, from development to production. With tools like Scribe Security’s blueprint, you can build a connected lineage, generate accurate SBOMs, assess your security posture, and visualize critical relationships within your development ecosystem. This level of insight empowers DevSecOps teams to identify vulnerabilities quickly, trace their origins, and maintain an up-to-date understanding of their software landscape—essential for staying ahead in today’s fast-paced and complex development environment.
Scribe offers a comprehensive solution for Discovery and governance as a critical enabler for securing your software supply chain:
- Initial and Deep Scans – Identifies and prioritizes assets like code repositories, pipelines, and container images across environments, building an inventory of relevant components.
- End-to-End Lineage – Connects isolated asset clusters using CLI tools and CI logs, forming a complete lineage from code to production.
- Software Bill of Materials (SBOM) – Generates accurate SBOMs by synthesizing artifact and repository data, excluding irrelevant dependencies.
- Security Posture Assessment – Continuously evaluates access controls, code signatures, and vulnerable dependencies to measure security KPIs.
- Visualization and Querying – Visualizes the entire SDLC and enables queries to trace vulnerabilities, orphaned workloads, and asset ownership.
- Flexible Deployment – Supports both SaaS and local deployments to meet varying security needs and control over sensitive data.
This content is brought to you by Scribe Security, a leading end-to-end software supply chain security solution provider – delivering state-of-the-art security to code artifacts and code development and delivery processes throughout the software supply chains. Learn more.
Related posts


