CVE (Common Vulnerabilities and Exposures) scans are essential to securing your software applications. However, with the increasing complexity of software stacks, identifying and addressing all CVEs can be challenging. One of the biggest issues with CVE scans today is the prevalence of false positives, where a vulnerability is identified in a package that is not in use in the production application.
It’s important to remember that even once you got a full list of all your software packages and a full list of all CVEs found in those packages it’s pretty certain that not all of them are relevant to your application. The CVE might be in a function that is not in use in your code, or in a part of the library you don’t even call. It might be in a transient dependency that is only called due to an unpatched dependency list and not in use in your code at all. Even once you know that a CVE is in a part of a library that you use, it’s no guarantee that the CVE is actually exploitable in your application. Some exploits take extreme conditions to be usable by hackers including the combination of 3 or more CVEs in sequence, the right stack, and the right infrastructure. Since you still need to take a closer look at each CVE you get from your scan you can see how important it is to winnow down the number of CVEs you get so that you won’t get alert fatigue or CVE burnout before you can get back to actually building your application’s next features.
In this article, I’ll offer some possible solutions to mitigate false positives in CVE scans, aiming to reduce the overall number of CVEs you need to deal with. I’ll start by discussing the challenges of identifying packages, and then move on to introducing a database that maps package files to package names. I’ll also discuss scoping and code path issues that can cause false positives.
Let’s start by looking at how CVEs are identified in the first place.
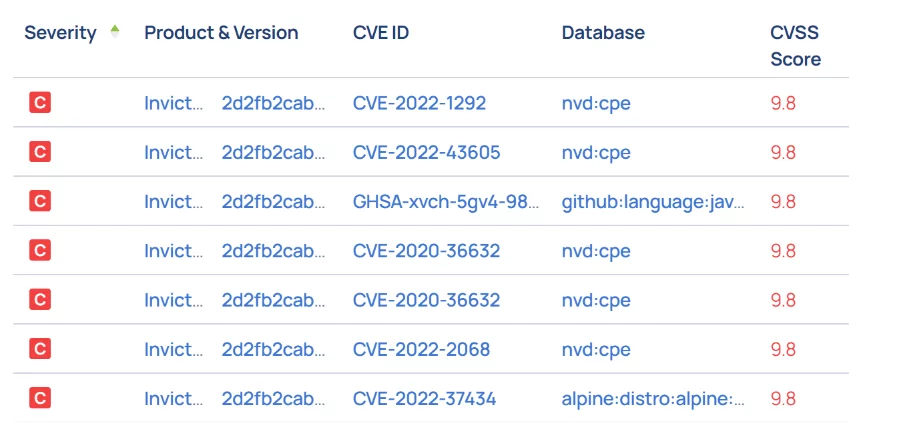
The Mystery Package and the Missing CVE
The Mitre Corporation is an American not-for-profit organization that is in charge of the CVE® program. The program’s mission is to Identify, define, and catalog publicly disclosed cybersecurity vulnerabilities. The way this works is that once you find a vulnerability you fill up a form and, if the find can be corroborated, a new CVE identifier is given to the vulnerability and it’s added to the public CVE database.
Considering the way CVEs are listed, one of the primary challenges with CVE scans is identifying packages and libraries correctly. When someone identifies a vulnerability in a package or a library, they list it with the package name and version they are familiar with. Of course, not all tools use the same naming conventions, and package names have no existing global standard. The ‘Naming Problem’, as it has come to be known, is severe enough that multiple forums and think groups have been trying to find a common ground solution for a long time. As an example, here’s OWASP’s proposed solution for the problem as it relates to the creation of SBOMs. Often, scanning tools rely on the sources they are fed, such as built or compiled artifacts, for the package names they deliver in the scan result and these sources are not always reliable. For example, wrappers and adaptations can make it difficult to identify the actual package. Additionally, some package files may not leave any trace of their installer package, such as Docker COPY commands.
To address these issues, we, at Scribe Security, suggest creating a database for your application that maps package files to package names. Even if the package name is different, if it’s the same package, the files, and the file hashes, would be identical. By doing so, you can skip issues involving wrappers and adaptations and identify the actual package that needs to be addressed. This approach can save time and effort in the CVE remediation process. Since the Scribe Platform is already identifying the files associated with each package included in your final image, creating such a database is the next logical step. We intend that our CVE scan would not need to rely on the name and version listed by the CVE, but on the actual files that the package includes.
Are You My Mommy?
When dealing with a final build that is a Docker image it’s common practice these days not to start from scratch. Having a solid starting point, such as an established base image, allows developers to focus on the part of the build that is their application rather than start planning the environment on which it needs to run. One of the challenges in using Docker images is understanding their provenance and dependencies, particularly when it comes to the parent image (apart from the base image) that the final image is built on top of.
The parent image is a concept we thought of to explain the closest ‘living relative’ of a Docker image. Images are built in distinct layers, so, let’s say that I use a known base image, such as Alpine, Debian, or Ubuntu, and build my application layer right on top of it. In this case, my closest ‘parent’ would be that base image. But what if the company I work for has a different starting point, one that includes a base image and a few more layers on top of that of security tools that are mandatory for all company images? In this case, my parent image would be this company template and I would also be able to identify the base image this template was built on.
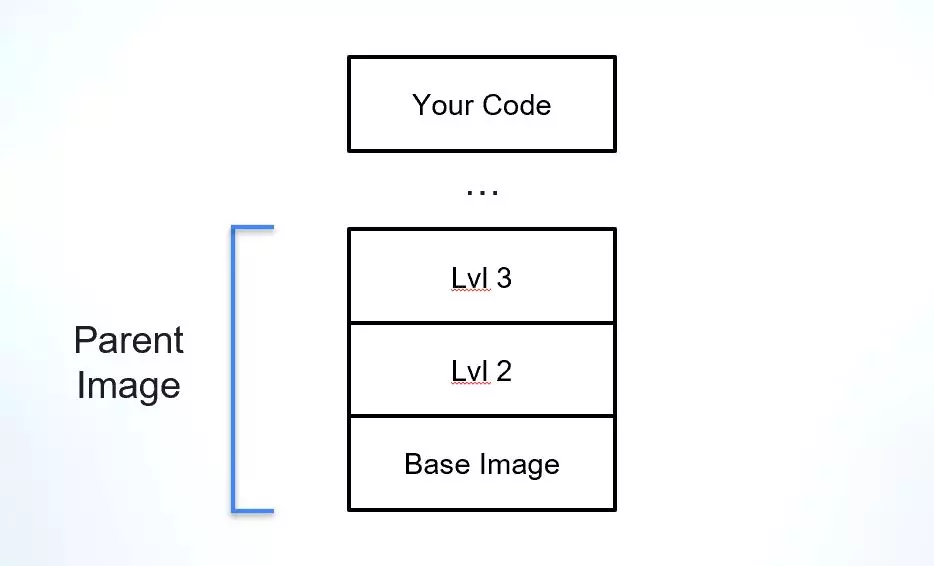
The Parent Image is a crucial part of your software supply chain, as it provides the foundation for the application and its dependencies. Natively, Docker images do not include much information about the origin of its parent or base images, making it difficult to verify its integrity, understand its vulnerabilities, and verify its license.
To address this issue, Scribe developed an open-source tool and service called ParentImage to detect the closest scanned parent of a Docker image. This tool can be used to identify the parent image of a Docker image, which is a key risk-reduction enabler:
First, by identifying the base image, one can verify its integrity and ensure that it has not been tampered with or compromised. This is important for maintaining the security and stability of the application.
Second, by understanding which vulnerabilities originate from the parent image and which originate from the application layer itself, one can prioritize and manage vulnerabilities more effectively. This means that CVEs that are linked to your base image or your parent image are less urgent (and not always your responsibility to remediate) when compared to CVEs in the application layer.
Additionally, by identifying the parent image, one can verify its license and ens ure compliance with legal and internal-policy requirements.
The ParentImage open-source tool includes an updatable database of Docker image scans. You can fork it and use it completely internally but we hope that people would scan their Docker Images and send us that information to be included in the database. The more image scans the database includes the more ‘Parents’ the tool would be able to identify. Currently, the included database has a full list of all established base images as a proof of concept. As an open-source tool, it costs nothing to give it a try so if you’re using Docker images I encourage you to consider this tool as a possible remedy to one reason for unrelated CVEs.
Should I Scan or Should I Skip?
Another challenge with CVE scans is scoping issues. Scoping refers to the location of files and packages scanned – what should be included in the scan and what can be safely ignored. Sometimes, a CVE is found in a package that is not actually in use in the production version of the application. For example, a package may be installed as a result of an indirect dependency on some testing framework. To address this, scanners need to assess the scope of the application files and identify the indirect dependencies in use.
OWASP (The Open Worldwide Application Security Project) plugins have some good examples of tools that can help with scoping issues. OWASP Dependency-Check, for instance, can analyze an application’s dependencies and identify CVEs in the context of the application’s dependency graph. By doing so, it can identify which CVEs are in use in the production application and which are not.
Whatever The Number, You Still Need To Address Your CVEs
In the absence of some other tool that would be able to tell you where your application is vulnerable to possible hacks, backdoors, and other such problems, a CVE scan is still a pretty basic option to address potential problems. The issue is, that until you verify if a CVE presented to you in the scan is an actual problem, it represents a threat that can be used against you by regulators, third parties, and users alike.
In the name of security and transparency, you need to go over every potential problem and prove that it’s either not a problem, not relevant to your application, or it is a potential problem and you’re working to patch it. The fact that a lot of these CVEs are coming into your application from external, usually open-source, packages means that even if you identify it as a potential exploit you would probably still need the help of the package maintainers to patch it.
With all this work associated with each CVE, it’s no wonder you’d prefer to get as small a number as possible in your next CVE scan. Using some of the suggestions outlined in this article might help make the monumental task of addressing your vulnerabilities a little more manageable.
If you have other open-source or free tools to deal with the problem we’d love to hear about it. Tell us about it in the comments and share with the community how you deal with your mountain of vulnerabilities.

This content is brought to you by Scribe Security, a leading end-to-end software supply chain security solution provider – delivering state-of-the-art security to code artifacts and code development and delivery processes throughout the software supply chains. Learn more.
Related posts


