The industry has not yet fully grasped the idea of an SBOM, and we already started hearing a new term – ML-BOM – Machine Learning Bill of Material. Before panic sets in, let’s understand why such a BOM should be produced, the challenges in generating an ML-BOM, and what such an ML-BOM can look like.
As you read this blog, you might ask yourself whether this article was AI-generated. The reason is that AI is all around us, and it’s hard to differentiate it from human-made artifacts. However, the rapid advancements in AI also pose private, commercial, and societal risks, and legislation is beginning to roll out to limit these risks, e.g., the EU AI Act. It is out of the scope of this article to delve deep into these risks, but to mention a few – there are risks of unsafe, discriminatory, and privacy-breaching behavior of AI-powered systems, as well as IP, licensing, and cyber-security risks.
A first step in handling these risks is to know which AI technologies are used within each system; such knowledge can enable stakeholders to manage the risks (e.g., manage legal risks by knowing the license of datasets and models) and to respond to new findings regarding these technologies (e.g., if a model is found to be discriminatory, the stakeholder can map all systems that use this model to mitigate the risk).
Glancing into the evolving regulation, examining Executive Order 13960 on “Promoting the Use of Trustworthy Artificial Intelligence in the Federal Government” reveals principles such as accountability, transparency, responsibility, traceability, and regulatory monitoring – all of which require understanding which AI technologies are used in each system.
An ML-BOM is a documentation of AI technologies within a product. CycloneDX, the well-known OWASP format for SBOM, version 1.5 and up, supports it and is now a standard for ML-BOM.
Generating an ML-BOM is challenging; there are many ways to represent models and datasets; AI models and datasets may be consumed on the fly, and the decision on which models to use may be made programmatically, on the fly, without leaving traces for standard component analysis technologies to detect them. On top of these challenges, AI is still an emerging technology, as opposed to the matureness of software package managers. So the industry does not yet fully understand the needs from an ML-BOM.
As a starting point, we have decided to focus on generating an ML-BOM for projects that use a de-facto standard, HuggingFace. HuggingFace is a “package manager” for AI models and datasets and is accompanied by popular Python libraries. Following are a few snapshots of an SBOM we automatically generated from such a product.
Imagine a product that consists of many components, some of them – machine learning models. The CycloneDX component below describes such a model:
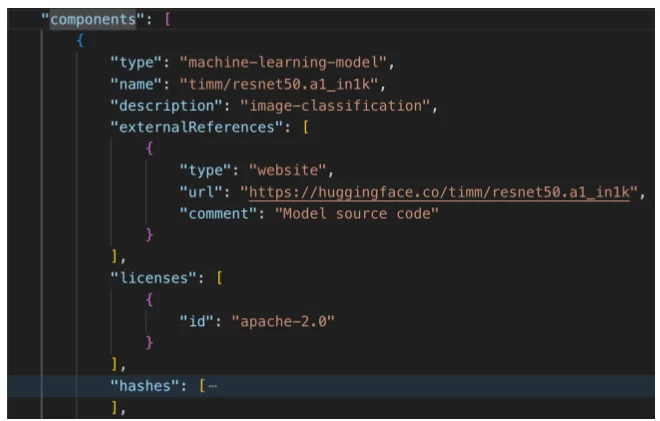
Machine-learning-model component (part 1) – standard CycloneDX component data
This component identifies the model and provides a link to explore information about this model further. In addition, it includes licensing information that can be used for compliance purposes.
CycloneDX V1.5 also defines an AI-specific field named “modelCard” as a standard way to document machine learning model properties. Following is an example of a modelCard we have created.
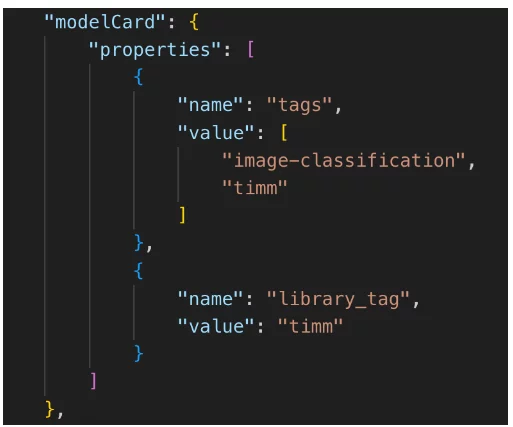
Machine-learning-model component (part 2) – data card
A use case for such a modelCard can be finding all products that use image classification models or running a policy that prevents using specific model types.
CycloneDX enables the documentation of a component tree – subcomponents hierarchy. Since HuggingFace, as an AI package manager, represents AI models and datasets as git-repos, We have decided to document the files of the AI model/ dataset as subcomponents of the machine learning model component. This is what it looks like:
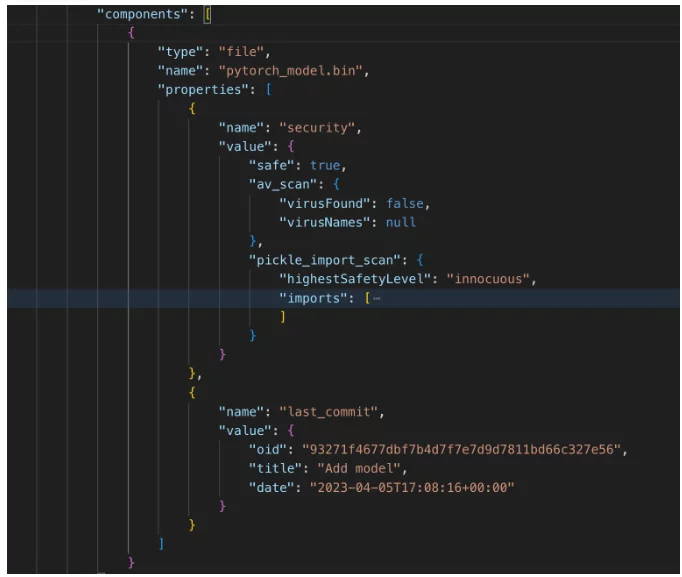
Machine-learning-model component (part 3) – sub-components
In addition to standard file information, the properties include additional information, such as security information. In this case, we see two security measures:
- Virus scanning – is important when consuming datasets susceptible to viruses (like images, PDFs, and executables).
- Pickle scanning – security-risk-measures regarding dataset files of “pickle” type, which are more risk-prone (to understand the risks in this format see explanation on the HuggingFace website).
This data can be used to enforce policies that verify that virus and pickle scanning has passed successfully.
ML-BOM is a new concept; what we show here is a first step. But even as such, we can understand the value it would bring given the rising adoption, regulation, and risks of AI.
As a final note, I asked my crystal ball (aka ChatGPT) to describe the future of ML-BOMs, and this was its answer:
“In the not-so-distant future, ML-BOMs might just evolve into cyber-savvy, autopiloting maestros, orchestrating the symphony of machine learning models with a flair of automation, all while tap-dancing through the intricacies of CI/CD pipelines.”
Well, maybe we need more than ML-BOMs…
This content is brought to you by Scribe Security, a leading end-to-end software supply chain security solution provider – delivering state-of-the-art security to code artifacts and code development and delivery processes throughout the software supply chains. Learn more.
Related posts